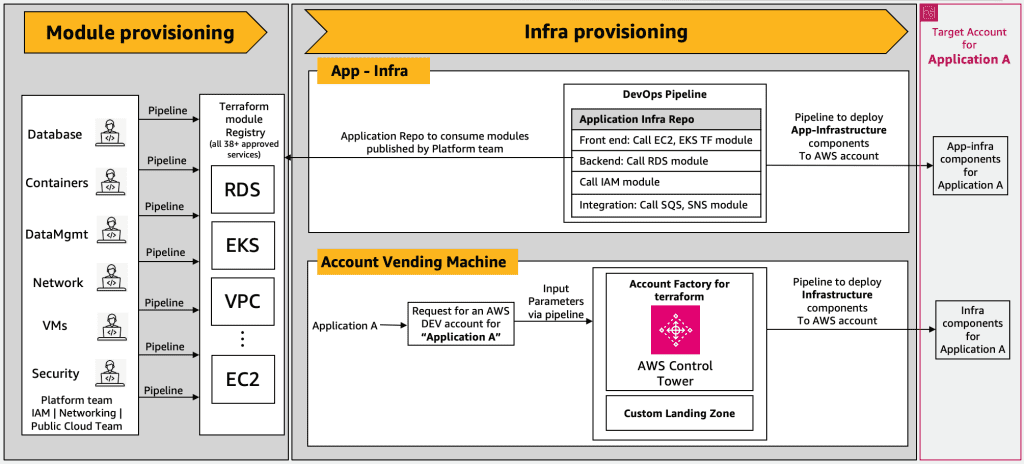
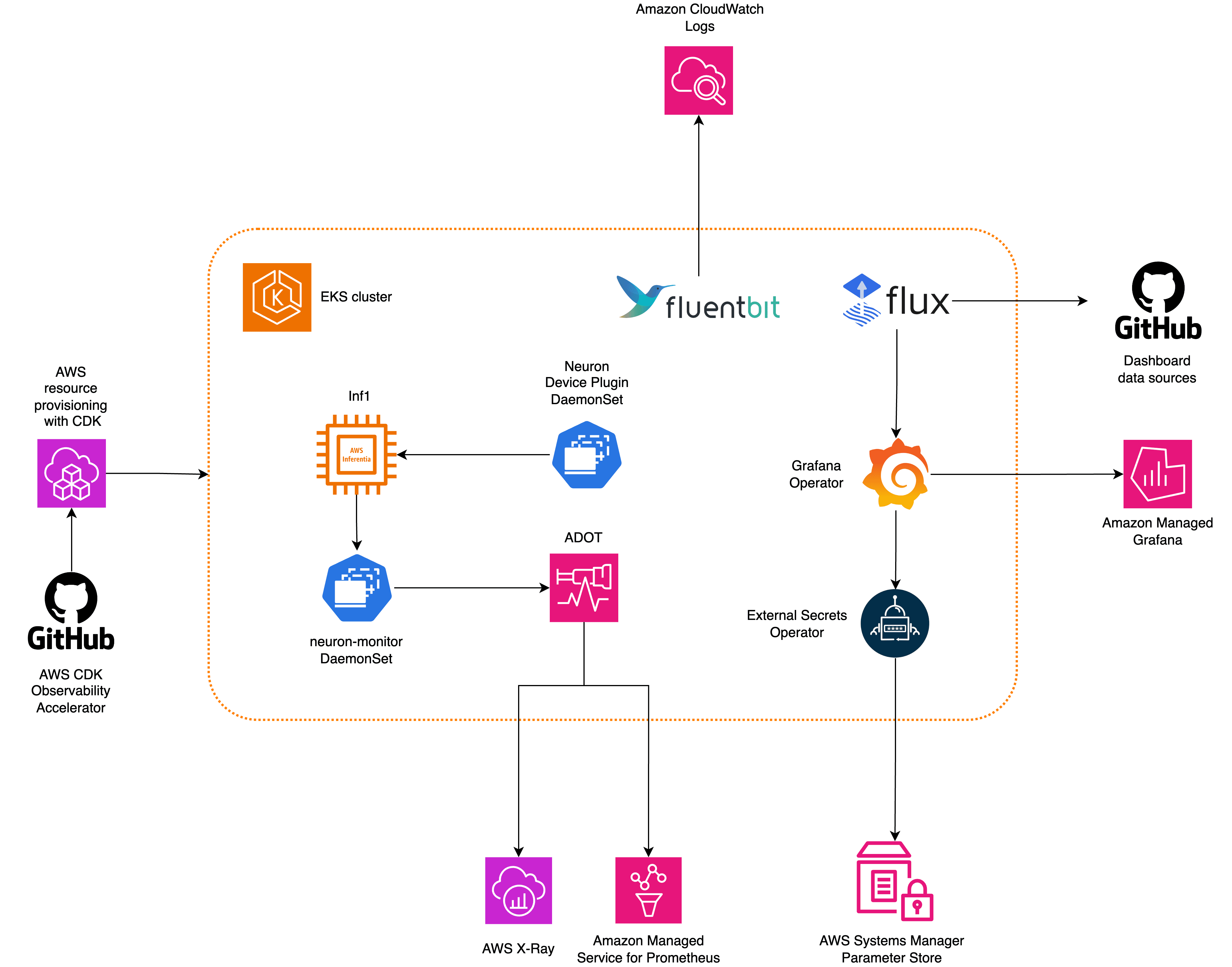
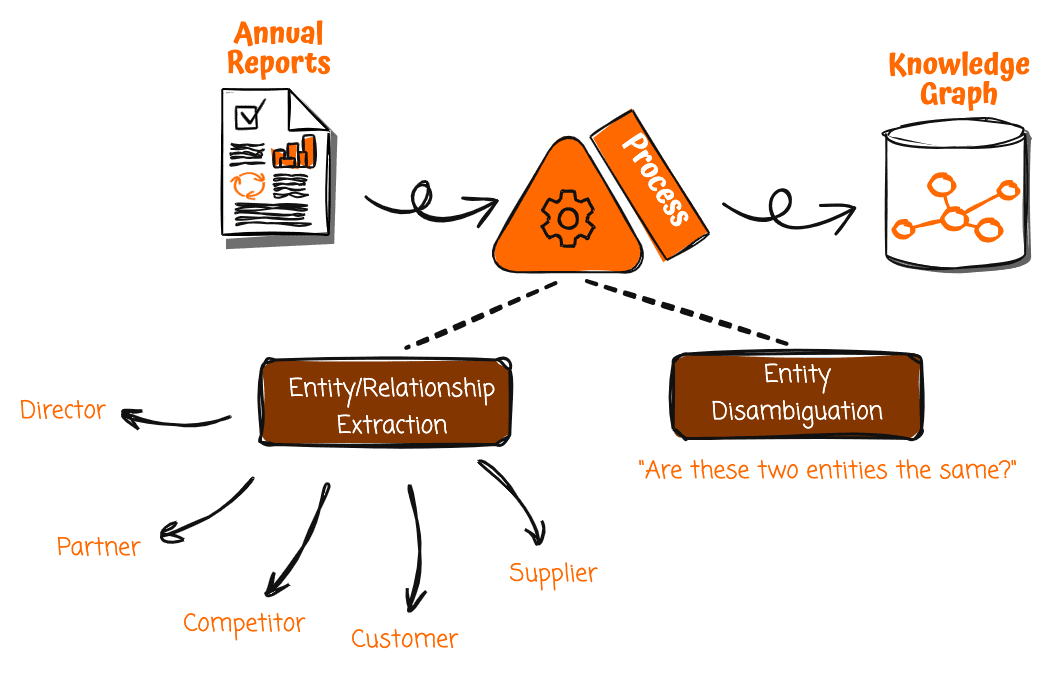
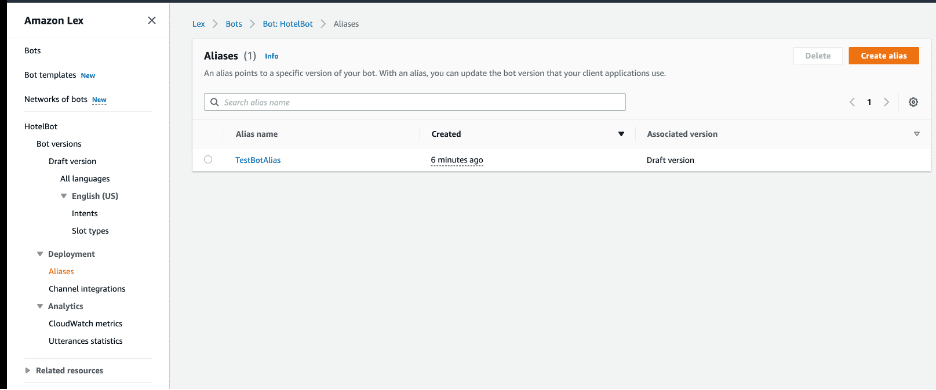
Meta Llama 3 models are now available in Amazon SageMaker JumpStart
Favorite Today, we are excited to announce that Meta Llama 3 foundation models are available through Amazon SageMaker JumpStart to deploy and run inference. The Llama 3 models are a collection of pre-trained and fine-tuned generative text models. In this post, we walk through how to discover and deploy Llama 3
Read More![]() Shared by AWS Machine Learning April 19, 2024
Shared by AWS Machine Learning April 19, 2024