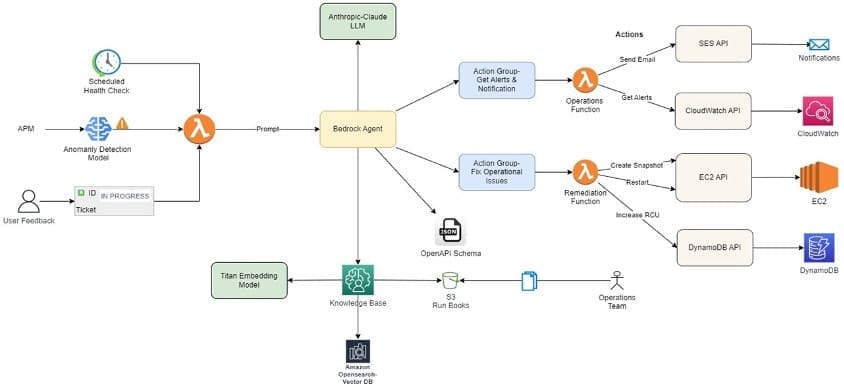
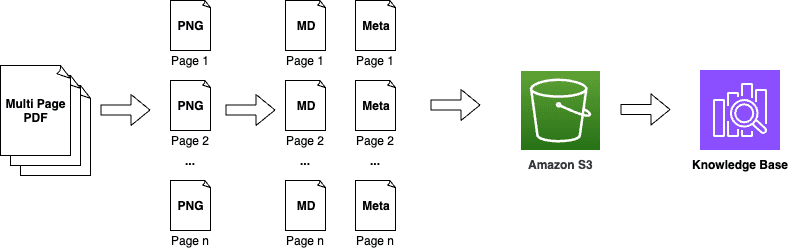
Generate training data and cost-effectively train categorical models with Amazon Bedrock

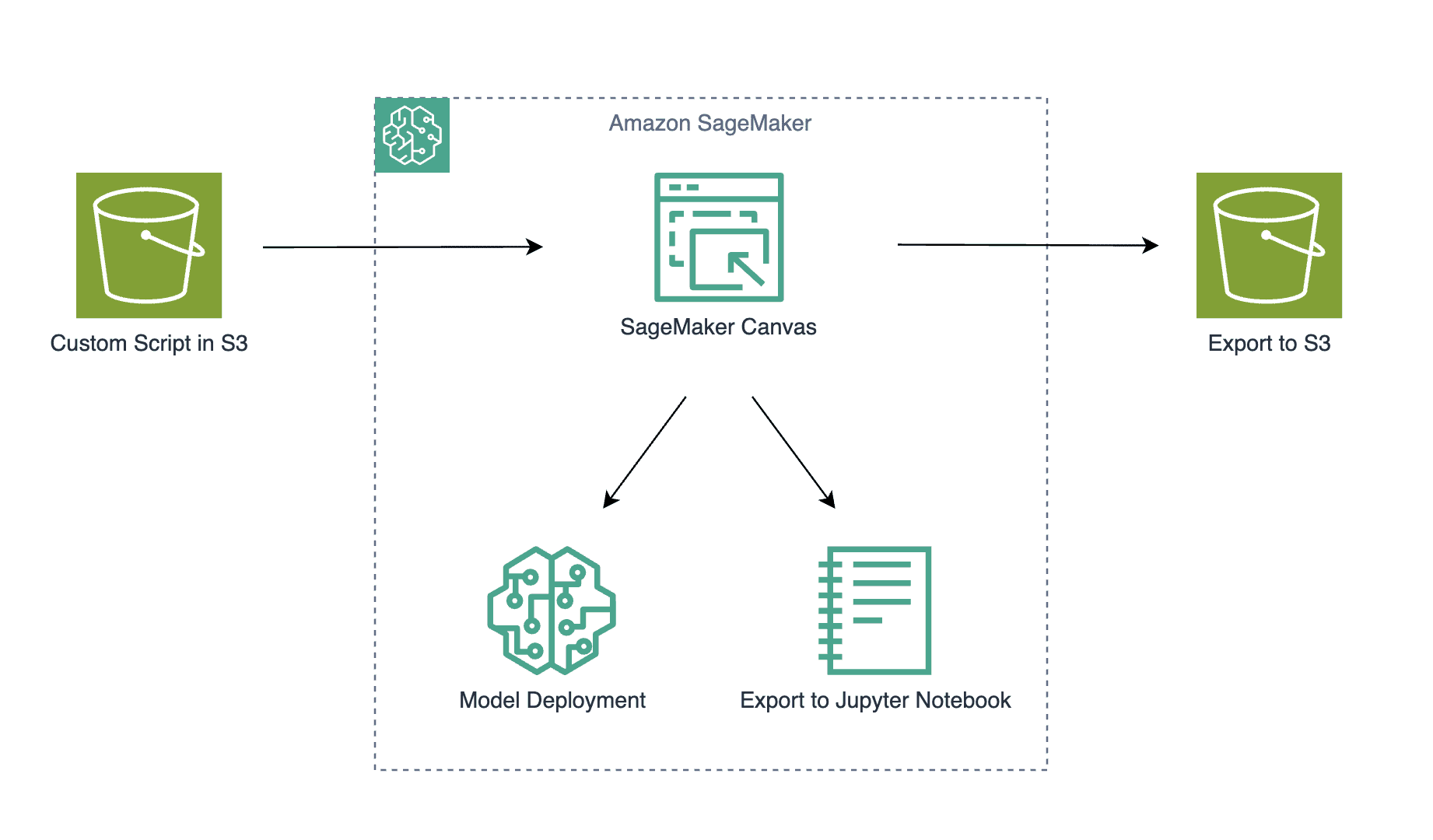
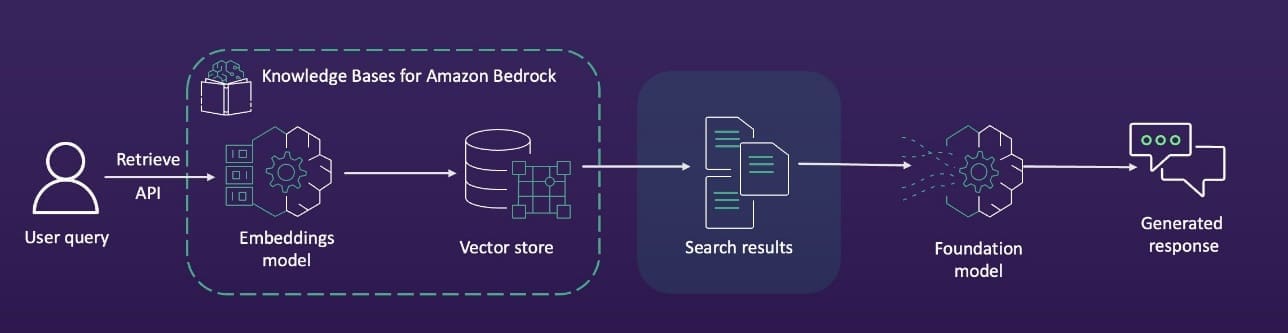
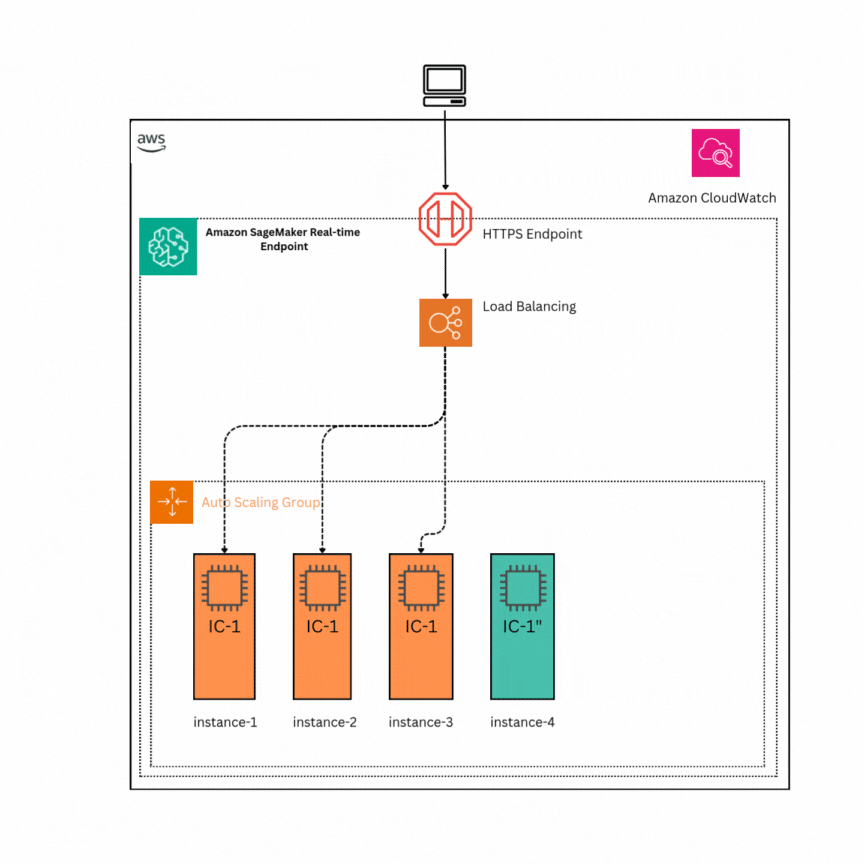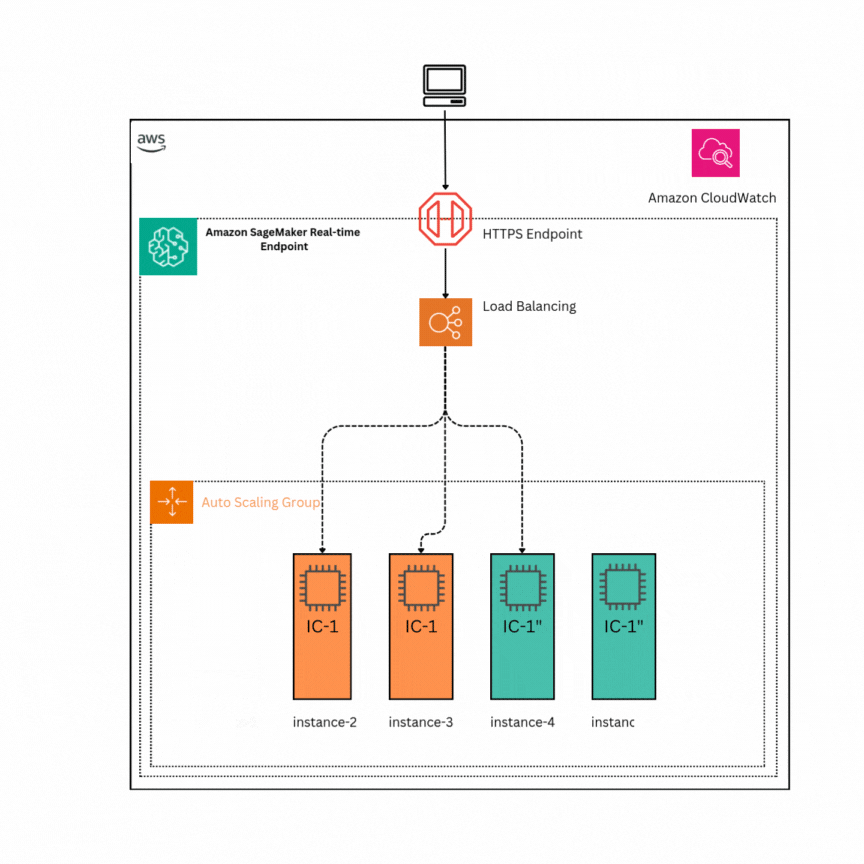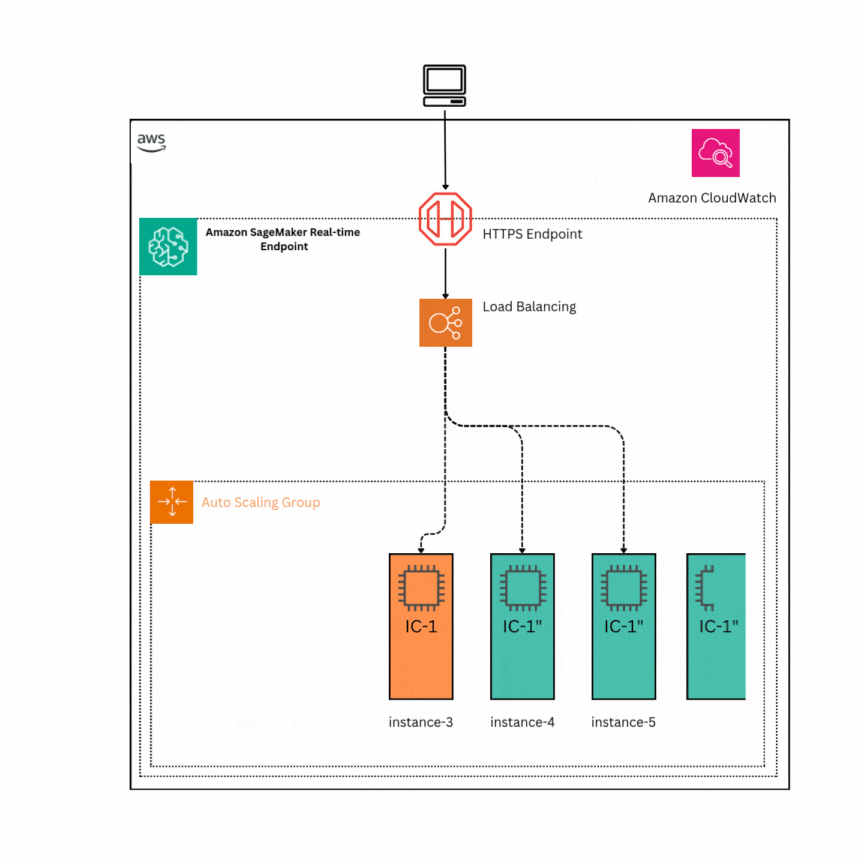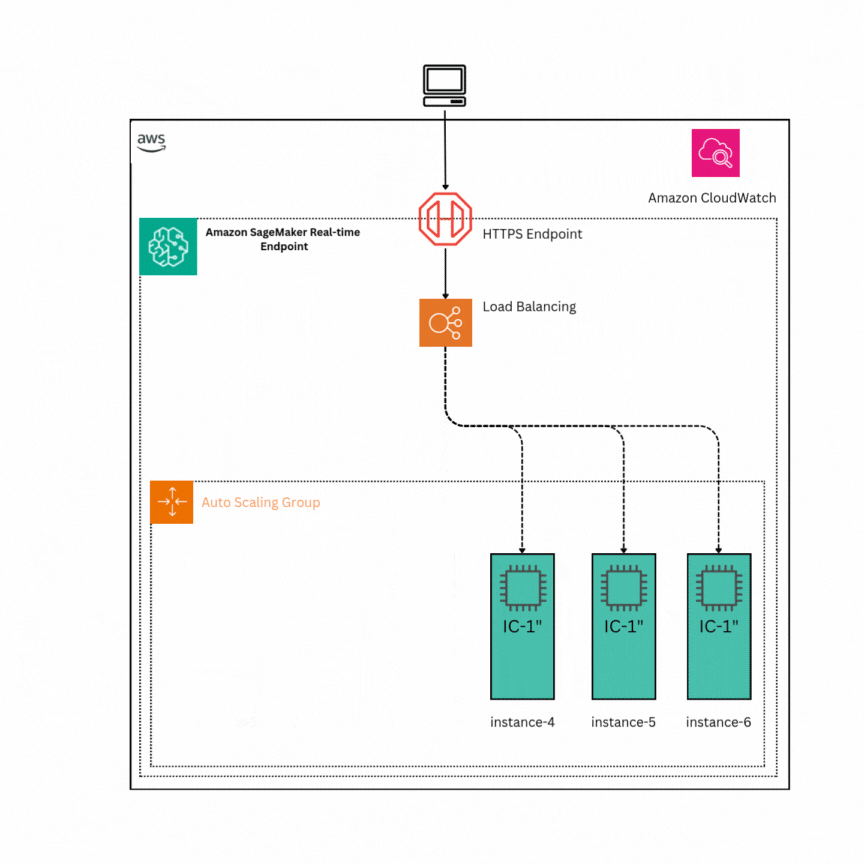
Favorite In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. Generative AI solutions can play an invaluable role during the model development phase by simplifying training and test
Read More![]() Shared by AWS Machine Learning March 27, 2025
Shared by AWS Machine Learning March 27, 2025