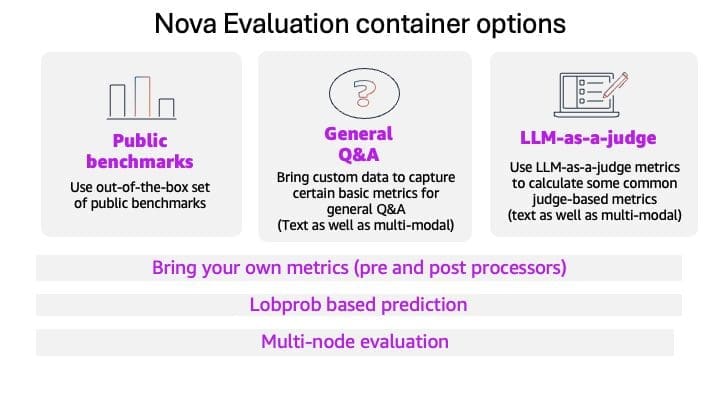
Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod
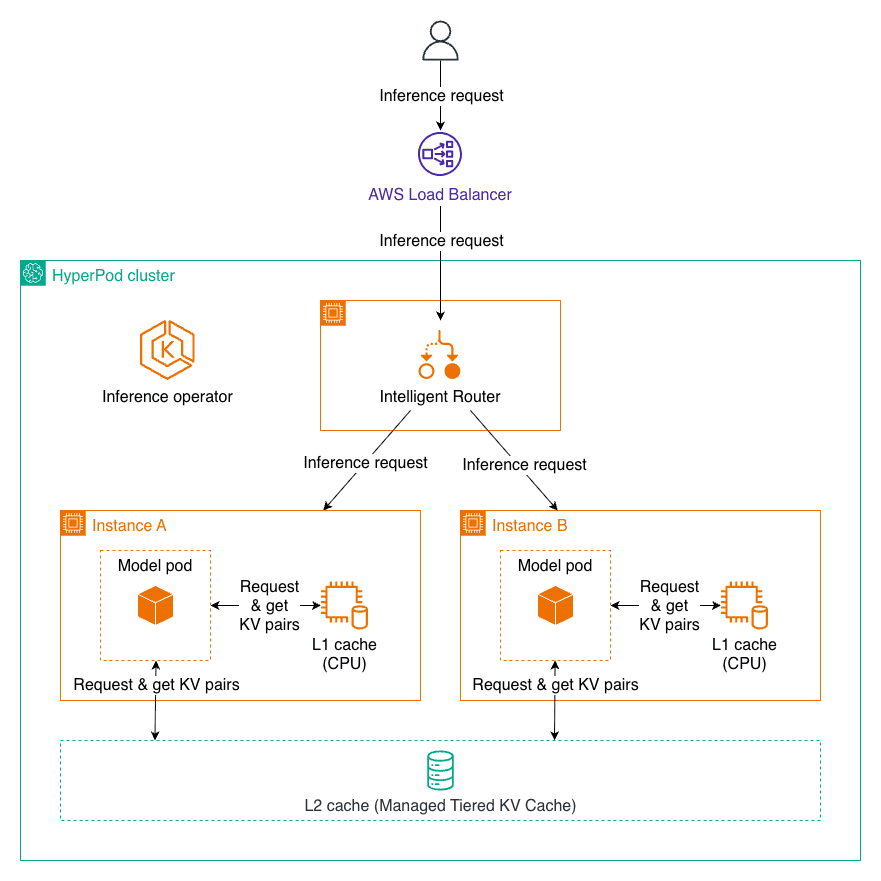
Favorite Modern AI applications demand fast, cost-effective responses from large language models, especially when handling long documents or extended conversations. However, LLM inference can become prohibitively slow and expensive as context length increases, with latency growing exponentially and costs mounting with each interaction. LLM inference requires recalculating attention mechanisms for
Read More![]() Shared by AWS Machine Learning November 27, 2025
Shared by AWS Machine Learning November 27, 2025