I/O 2026
Favorite At Google I/O 2026, we shared how we’re making AI more helpful for everyone. See everything we announced. View Original Source (blog.google/technology/ai/) Here.

A Technology Broker and Management Company Specializing in KM Systems
Favorite At Google I/O 2026, we shared how we’re making AI more helpful for everyone. See everything we announced. View Original Source (blog.google/technology/ai/) Here.
Favorite One year after launch, see how AI Mode’s users are shifting from keywords to natural language queries. View Original Source (blog.google/technology/ai/) Here.
Favorite Announcing new voice capabilities in Gmail, Docs and Keep, a new design tool called Google Pics and updates to AI Inbox. View Original Source (blog.google/technology/ai/) Here.
Favorite The latest from Google I/O: See how we’re helping you get more done with Gemini. View Original Source (blog.google/technology/ai/) Here.
Favorite At Google I/O we released Gemini 3.5, our latest series of models combining frontier intelligence with action. View Original Source (blog.google/technology/ai/) Here.
Favorite Introducing a $100 AI Ultra plan — plus, new features and benefits for Google AI Plus, Pro and Ultra subscribers. View Original Source (blog.google/technology/ai/) Here.
Favorite We shared the next step in our journey to bring together the best of a search engine with the best of AI. View Original Source (blog.google/technology/ai/) Here.
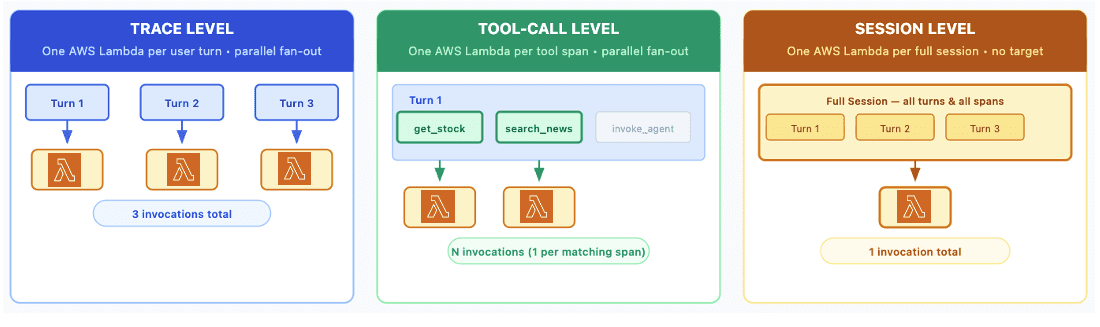
Favorite Special thanks to everyone who contributed to this launch: Stephanie Yuan, Lefan Zhang, Ritvika Pillai, Irene Wang, Carter Williams, T.J Ariyawansa, Gitika Jha, Shoaib Javed and the product leadership from Vivek Singh. Moving prototype agents to production requires measuring quality across multiple dimensions. Amazon Bedrock AgentCore Evaluations provides large
Read More![]() Shared by AWS Machine Learning May 19, 2026
Shared by AWS Machine Learning May 19, 2026
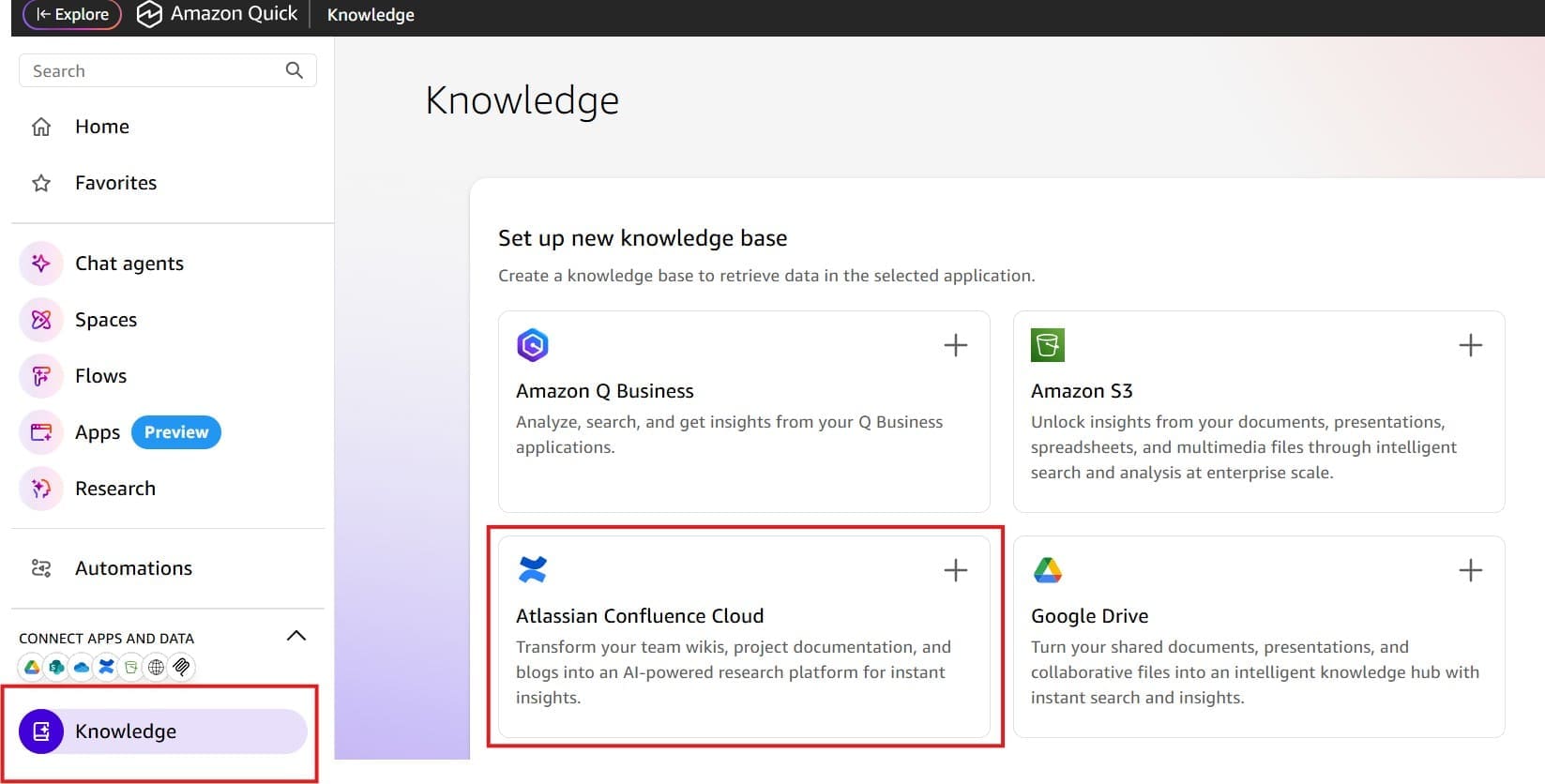
Favorite Teams can integrate Atlassian Confluence Cloud with Amazon Quick to search and manage documentation without switching between multiple systems. When documentation lives in Confluence, but related data sits in other systems, teams waste time switching tools, re-searching for context, and manually gathering information. These interruptions slow decisions and create
Read More![]() Shared by AWS Machine Learning May 18, 2026
Shared by AWS Machine Learning May 18, 2026
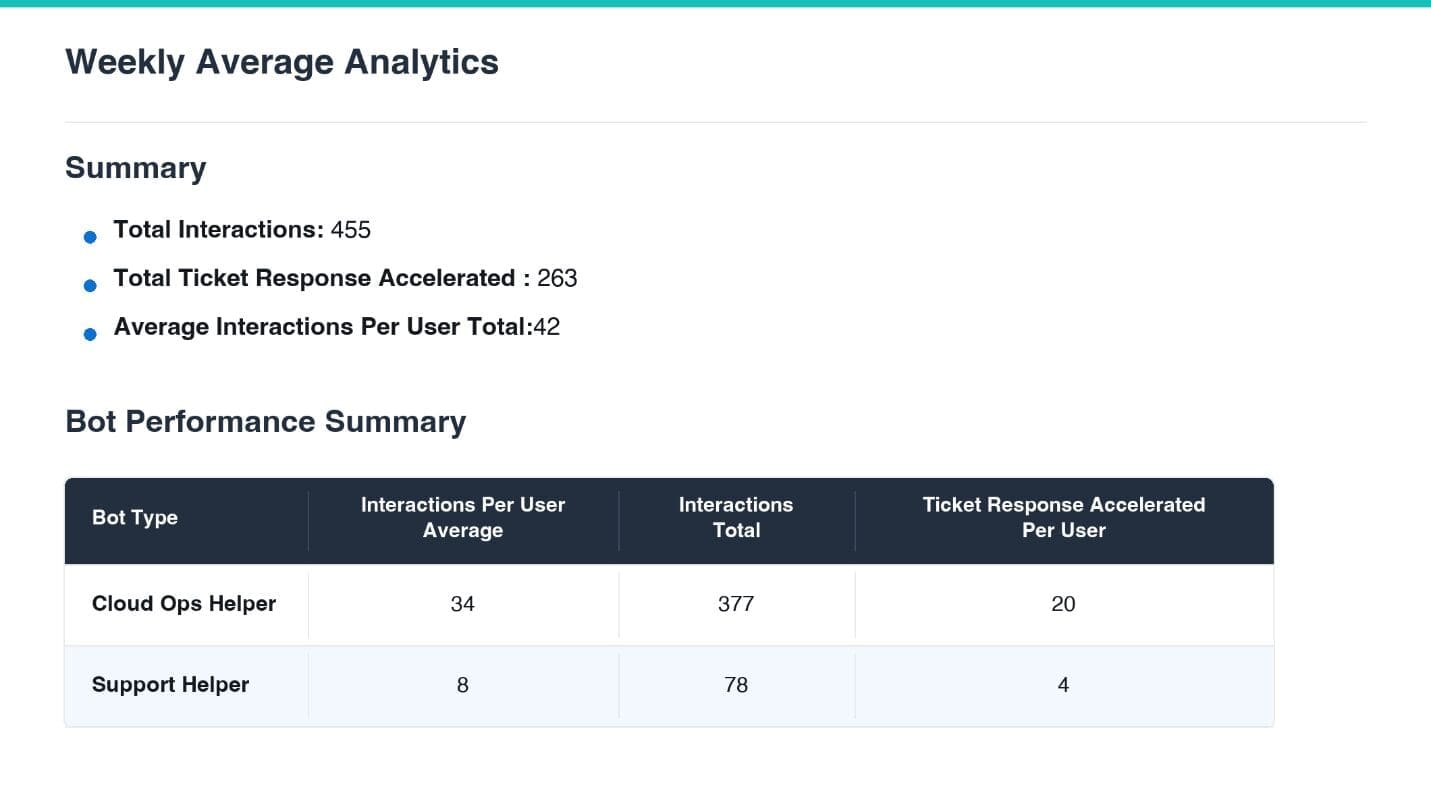
Favorite This guest post is co-written by Angela Mapes and Adam Walker of Aderant. Aderant, a leading global provider of comprehensive business management software for the legal industry, transformed how its 38-person Cloud Engineering team supports Expert Sierra, its cloud-based legal practice management solution. By implementing Amazon Quick, Aderant has
Read More![]() Shared by AWS Machine Learning May 18, 2026
Shared by AWS Machine Learning May 18, 2026