Favorite For more than a decade, Google Research has been using AI to precisely map the connections between every cell in the brain in an endeavor called connectomics. Now, in co… View Original Source (blog.google/technology/ai/) Here.
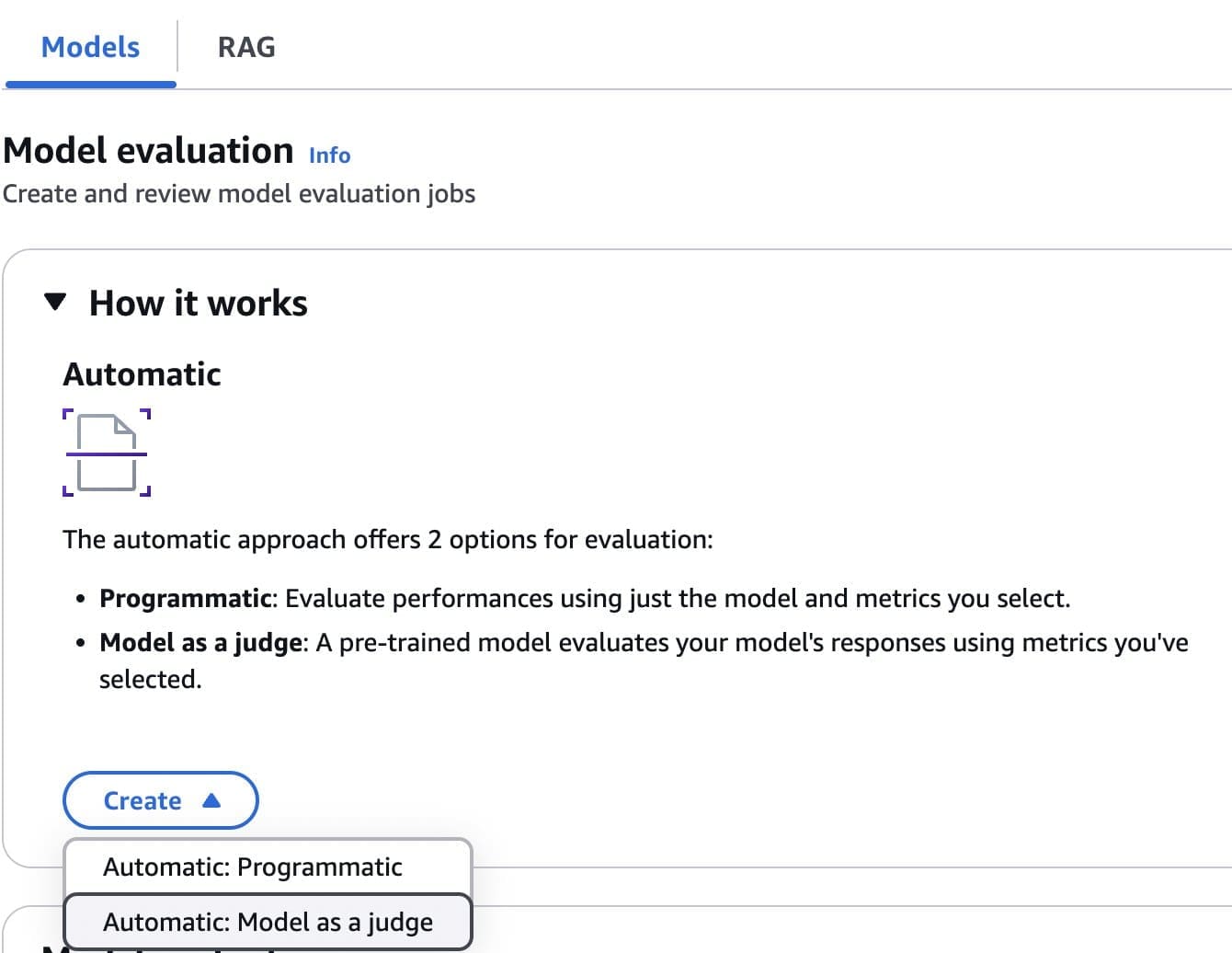
Favorite With Amazon Bedrock Evaluations, you can evaluate foundation models (FMs) and Retrieval Augmented Generation (RAG) systems, whether hosted on Amazon Bedrock or another model or RAG system hosted elsewhere, including Amazon Bedrock Knowledge Bases or multi-cloud and on-premises deployments. We recently announced the general availability of the large language
Read More
 Shared by AWS Machine Learning May 7, 2025
Shared by AWS Machine Learning May 7, 2025
Favorite Here are Google’s latest AI updates from April 2025 View Original Source (blog.google/technology/ai/) Here.
Favorite When you’re trying to learn about something new on the web, you might come across content that uses jargon or technical concepts you’re not familiar with. Simplify, a ne… View Original Source (blog.google/technology/ai/) Here.
Favorite We’re introducing the first 49 recipients of the Google.org AI Opportunity Fund: Asia-Pacific and announcing the Fund’s expansion by $12 million. View Original Source (blog.google/technology/ai/) Here.
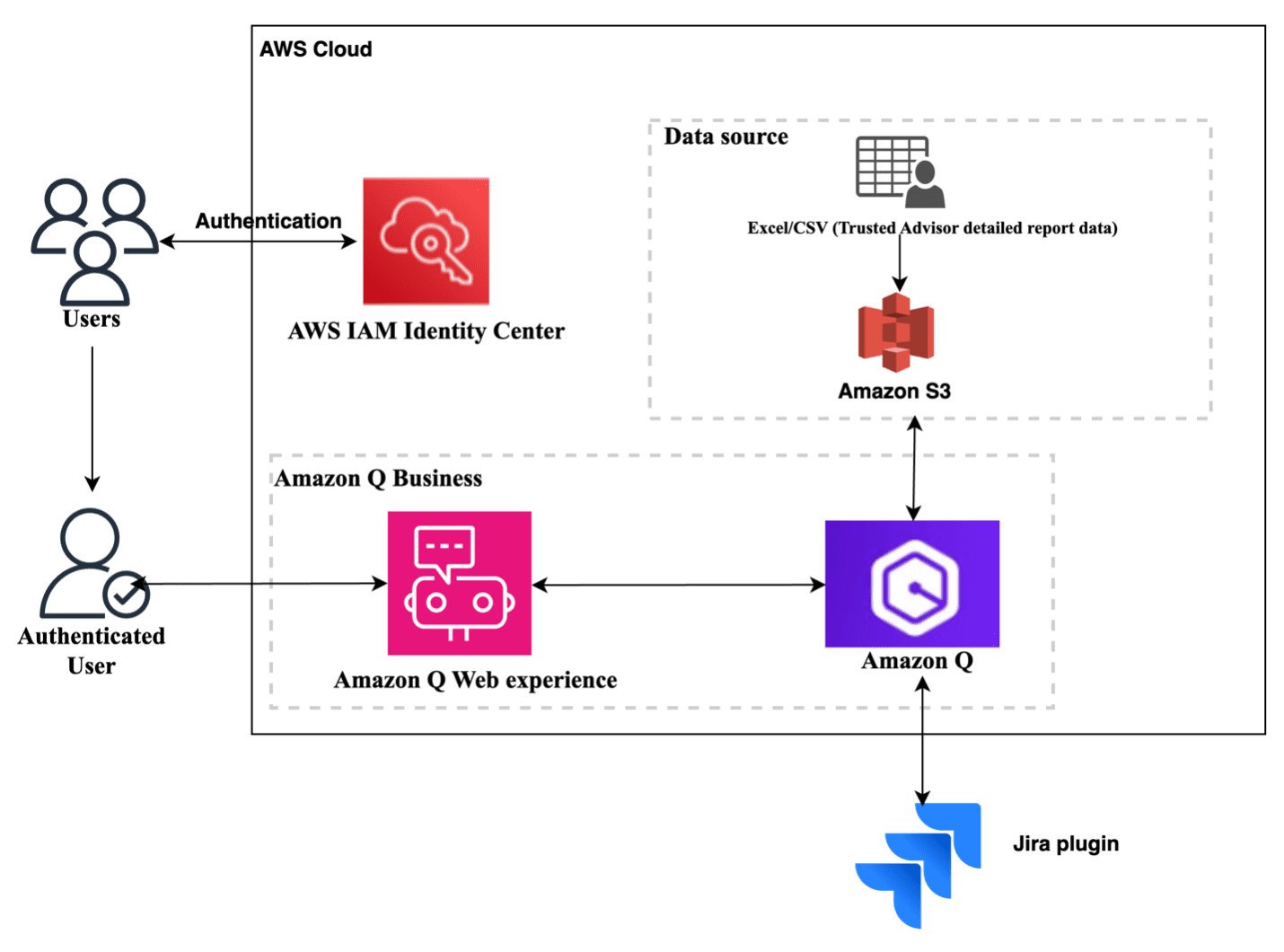
Favorite Our customers’ key strategic objectives are cost savings and building secure and resilient infrastructure. At AWS, we’re dedicated to helping you meet these critical goals with our unparalleled expertise and industry-leading tools. One of the most valuable resources we offer is the AWS Trusted Advisor detailed report, which provides
Read More
Shared by AWS Machine Learning May 3, 2025
Favorite In this post, we showcase how Dr. Kori Ramajoo, Dr. Sonia Brownsett, Prof. David Copland, from QARC, and Scott Harding, a person living with aphasia, used AWS services to develop WordFinder, a mobile, cloud-based solution that helps individuals with aphasia increase their independence through the use of AWS generative
Read More
Shared by AWS Machine Learning May 3, 2025
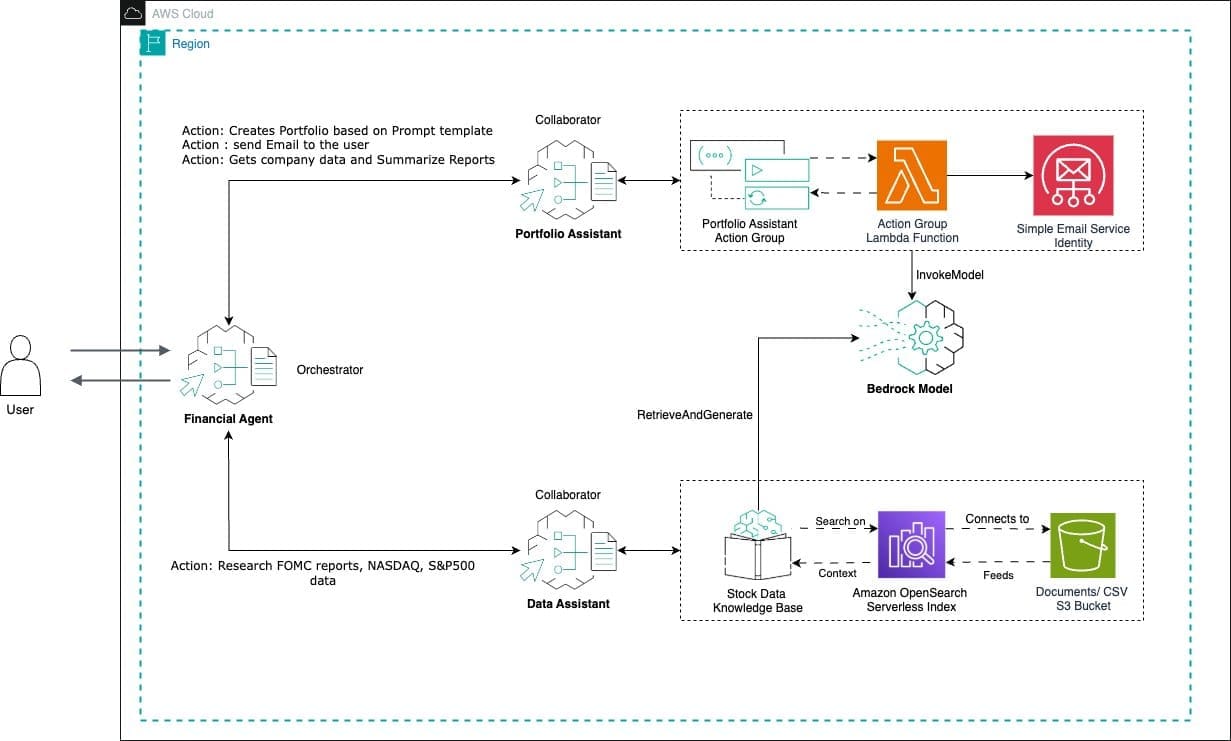
Favorite The Amazon Bedrock multi-agent collaboration feature gives developers the flexibility to create and coordinate multiple AI agents, each specialized for specific tasks, to work together efficiently on complex business processes. This enables seamless handling of sophisticated workflows through agent cooperation. This post aims to demonstrate the application of multiple
Read More
Shared by AWS Machine Learning May 3, 2025
Favorite Learn more about the startups chosen for Google for Startups Accelerator: AI for Nature. View Original Source (blog.google/technology/ai/) Here.
Favorite The latest episode of the Google AI: Release Notes podcast focuses on long context in Gemini — meaning how much information our AI models can process as input at once — … View Original Source (blog.google/technology/ai/) Here.