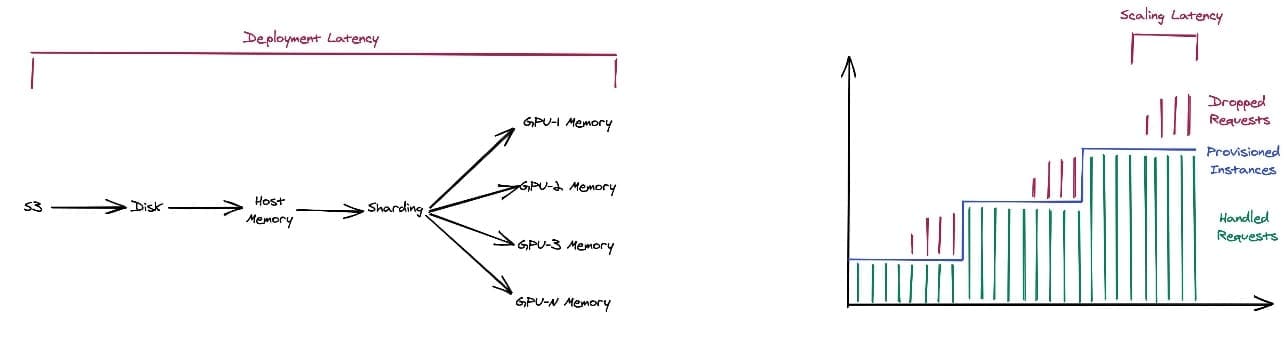
Favorite The generative AI landscape has been rapidly evolving, with large language models (LLMs) at the forefront of this transformation. These models have grown exponentially in size and complexity, with some now containing hundreds of billions of parameters and requiring hundreds of gigabytes of memory. As LLMs continue to expand,
Read More
 Shared by AWS Machine Learning December 3, 2024
Shared by AWS Machine Learning December 3, 2024
Favorite Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AI models for inference. This innovation allows you to scale your models faster, observing up to 56% reduction in latency when scaling
Read More
Shared by AWS Machine Learning December 3, 2024
Favorite Today at AWS re:Invent 2024, we are excited to announce a new feature for Amazon SageMaker inference endpoints: the ability to scale SageMaker inference endpoints to zero instances. This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in
Read More
Shared by AWS Machine Learning December 3, 2024
Favorite This post is co-written with Abhishek Sawarkar, Eliuth Triana, Jiahong Liu and Kshitiz Gupta from NVIDIA. At re:Invent 2024, we are excited to announce new capabilities to speed up your AI inference workloads with NVIDIA accelerated computing and software offerings on Amazon SageMaker. These advancements build upon our collaboration
Read More
Shared by AWS Machine Learning December 3, 2024
Favorite Google and Kaggle recently launched a five-day intensive course about generative AI. View Original Source (blog.google/technology/ai/) Here.
Favorite As developers gear up for re:Invent 2024, they again face the unique challenges of physical racing. What are the obstacles? Let’s have a look. In this blog post, I will look at what makes physical AWS DeepRacer racing—a real car on a real track—different to racing in the virtual
Read More
Shared by AWS Machine Learning December 2, 2024
Favorite We are excited to announce the availability of Cohere’s advanced reranking model Rerank 3.5 through our new Rerank API in Amazon Bedrock. This powerful reranking model enables AWS customers to significantly improve their search relevance and content ranking capabilities. This model is also available for Amazon Bedrock Knowledge Base
Read More
Shared by AWS Machine Learning December 2, 2024
Favorite Prompt engineering refers to the practice of writing instructions to get the desired responses from foundation models (FMs). You might have to spend months experimenting and iterating on your prompts, following the best practices for each model, to achieve your desired output. Furthermore, these prompts are specific to a
Read More
Shared by AWS Machine Learning November 30, 2024
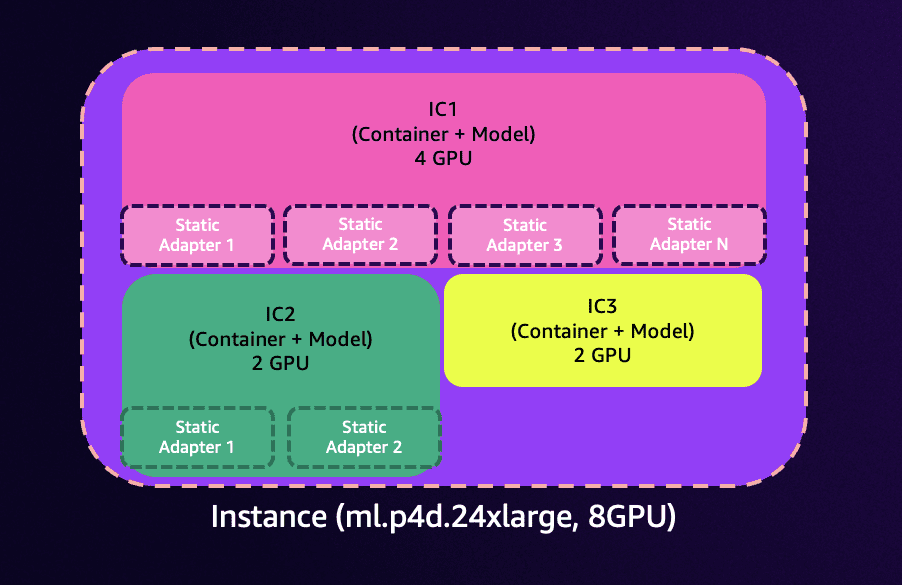
Favorite The new efficient multi-adapter inference feature of Amazon SageMaker unlocks exciting possibilities for customers using fine-tuned models. This capability integrates with SageMaker inference components to allow you to deploy and manage hundreds of fine-tuned Low-Rank Adaptation (LoRA) adapters through SageMaker APIs. Multi-adapter inference handles the registration of fine-tuned adapters
Read More
Shared by AWS Machine Learning November 30, 2024
Favorite Seamless integration of customer experience, collaboration tools, and relevant data is the foundation for delivering knowledge-based productivity gains. In this post, we show you how to integrate the popular Slack messaging service with AWS generative AI services to build a natural language assistant where business users can ask questions
Read More
Shared by AWS Machine Learning November 28, 2024