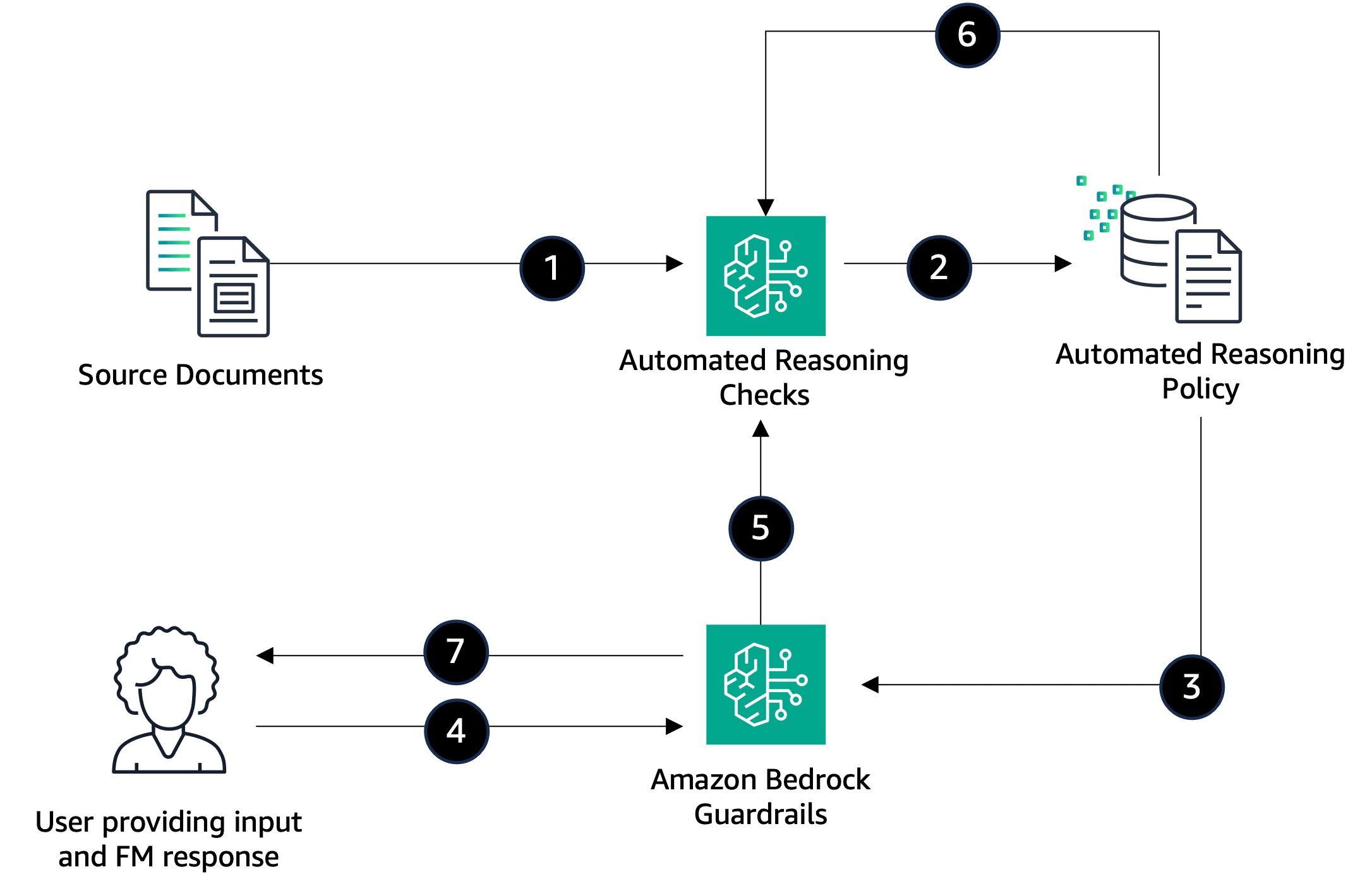
Favorite Foundational models (FMs) and generative AI are transforming how financial service institutions (FSIs) operate their core business functions. AWS FSI customers, including NASDAQ, State Bank of India, and Bridgewater, have used FMs to reimagine their business operations and deliver improved outcomes. FMs are probabilistic in nature and produce a
Read More
 Shared by AWS Machine Learning February 19, 2025
Shared by AWS Machine Learning February 19, 2025
Favorite Use Google Lens to search your screen within the Google app or Chrome on iOS. Plus, AI Overviews are coming to more Lens queries. View Original Source (blog.google/technology/ai/) Here.
Favorite Today we’re announcing new creative capabilities in Google Ads to help brands generate lifestyle imagery. View Original Source (blog.google/technology/ai/) Here.
Favorite Today Google is launching an AI co-scientist, a new AI system built on Gemini 2.0 designed to aid scientists in creating novel hypotheses and research plans. Researchers… View Original Source (blog.google/technology/ai/) Here.
Favorite An overview of our latest expert tools in Flood Hub and our partnerships to support vulnerable communities. View Original Source (blog.google/technology/ai/) Here.
Favorite A year ago we called on Meta to stop calling Llama 2 “Open Source.” Since then, Meta has released new versions of Llama with new licensing terms that continue to fail the Open Source Definition. Llama 3.x is still not Open Source by any stretch of the imagination. Despite
Read More
Shared by voicesofopensource February 18, 2025
Favorite Cycling is a fun way to stay fit, enjoy nature, and connect with friends and acquaintances. However, riding is becoming increasingly dangerous, especially in situations where cyclists and cars share the road. According to the NHTSA, in the United States an average of 883 people on bicycles are killed
Read More
Shared by AWS Machine Learning February 17, 2025
Favorite In this post, we discuss what embeddings are, show how to practically use language embeddings, and explore how to use them to add functionality such as zero-shot classification and semantic search. We then use Amazon Bedrock and language embeddings to add these features to a really simple syndication (RSS)
Read More
Shared by AWS Machine Learning February 14, 2025
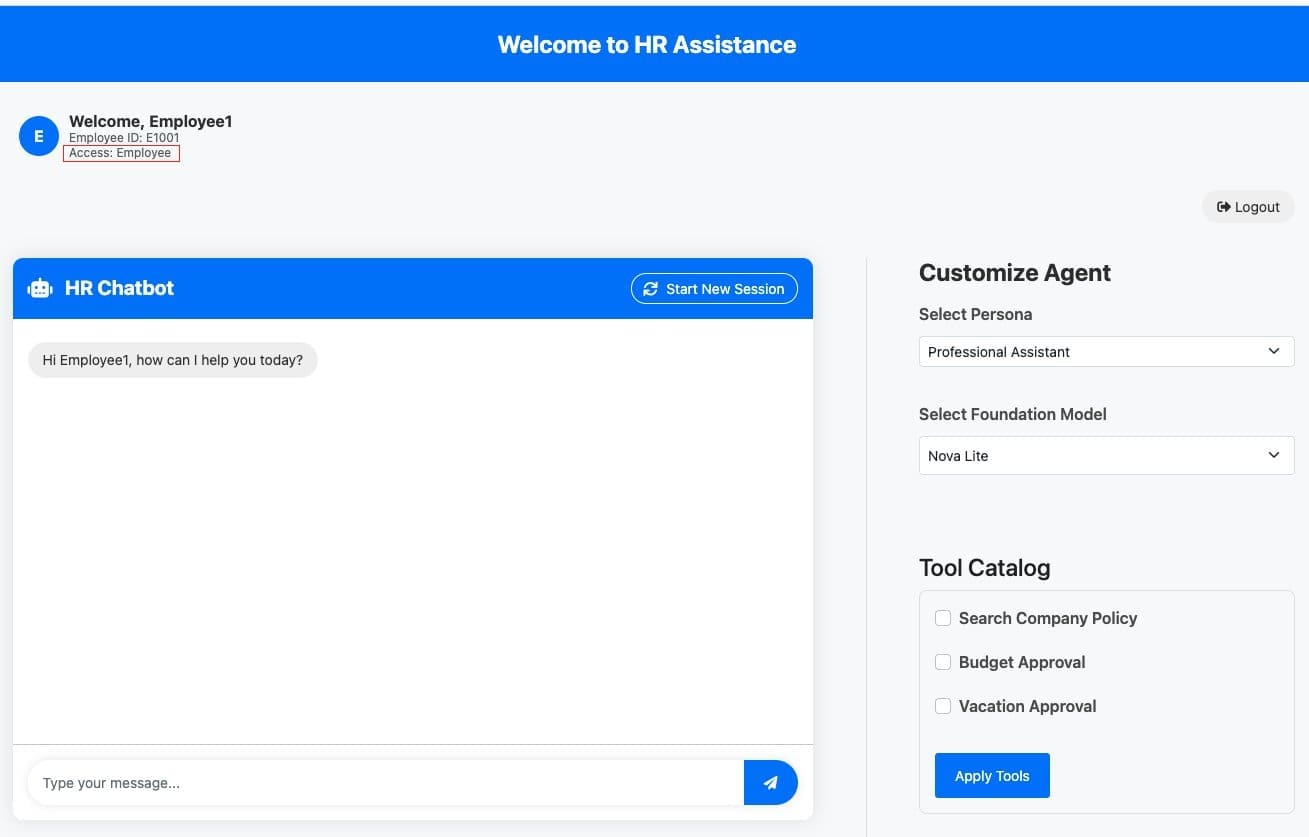
Favorite AI agents continue to gain momentum, as businesses use the power of generative AI to reinvent customer experiences and automate complex workflows. We are seeing Amazon Bedrock Agents applied in investment research, insurance claims processing, root cause analysis, advertising campaigns, and much more. Agents use the reasoning capability of
Read More
Shared by AWS Machine Learning February 14, 2025
Favorite 39 students in Ireland from underrepresented backgrounds have been awarded scholarships to study STEM courses, with Google.org support. View Original Source (blog.google/technology/ai/) Here.