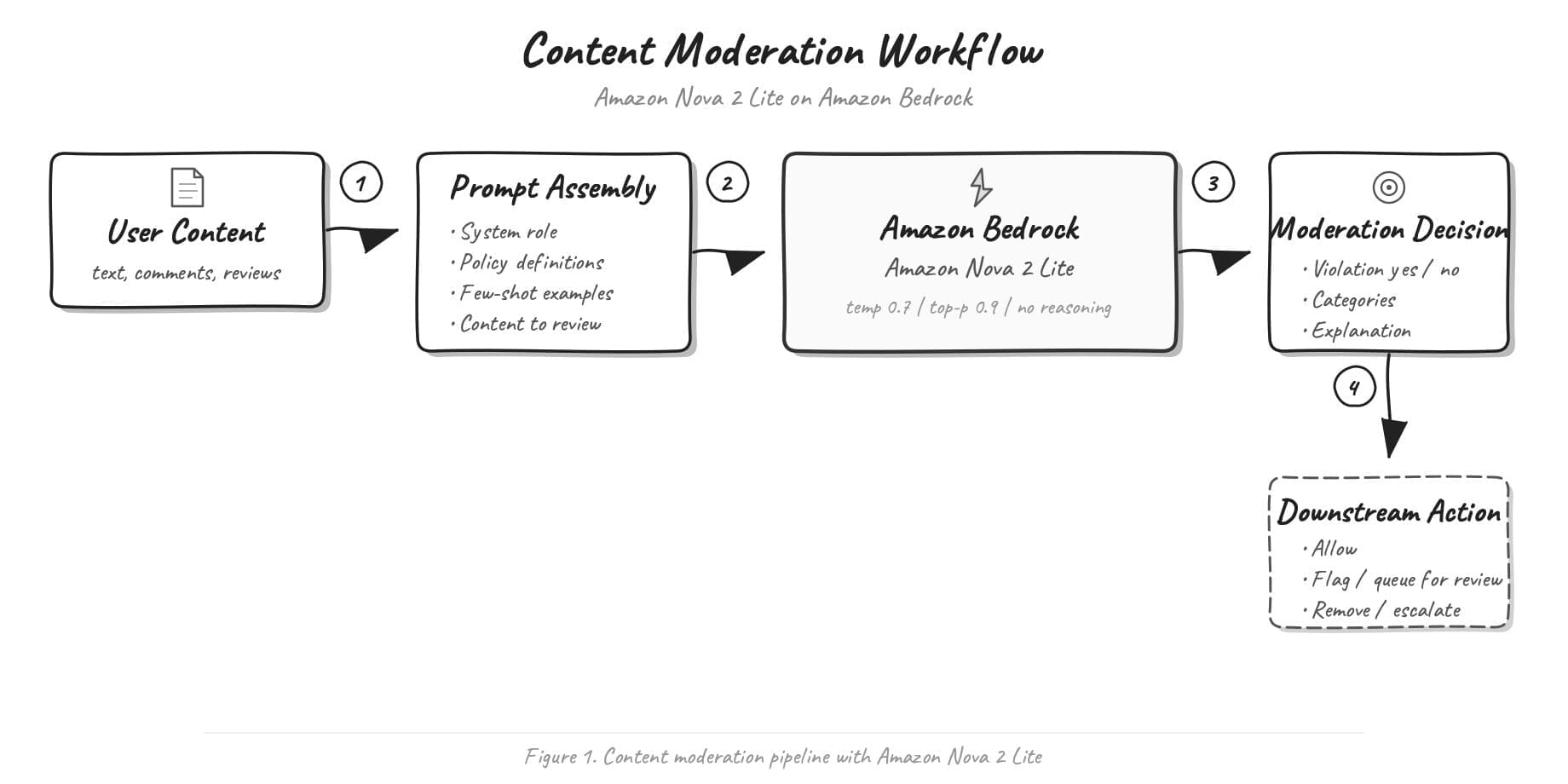
Favorite If you moderate user-generated content at scale, you need a system that catches policy violations accurately without over-flagging legitimate posts. A moderation system that misses harmful content puts you at risk, while one that flags too aggressively frustrates your audience. Every organization defines its own policies, so a single
Read More
 Shared by AWS Machine Learning May 18, 2026
Shared by AWS Machine Learning May 18, 2026
Favorite The Open Source Initiative (OSI) is pleased to support the inaugural Open Technology Research (OTR) Symposium 2026, taking place on 26–27 October 2026 at the historic University of Barcelona. Organized by the Open Source Initiative (OSI), OpenForum Europe (OFE), Open Knowledge Foundation (OKFN), and the Digital Infrastructure Insights Fund
Read More
Shared by voicesofopensource May 18, 2026
Favorite Organizations that must restrict access to sensitive documents increasingly rely on AI-driven search and chat to help employees find answers across large repositories. Coarse-grained permissions that control access at the knowledge base level work well for many teams, but sensitive documents require more granular control to restrict specific documents
Read More
Shared by AWS Machine Learning May 15, 2026
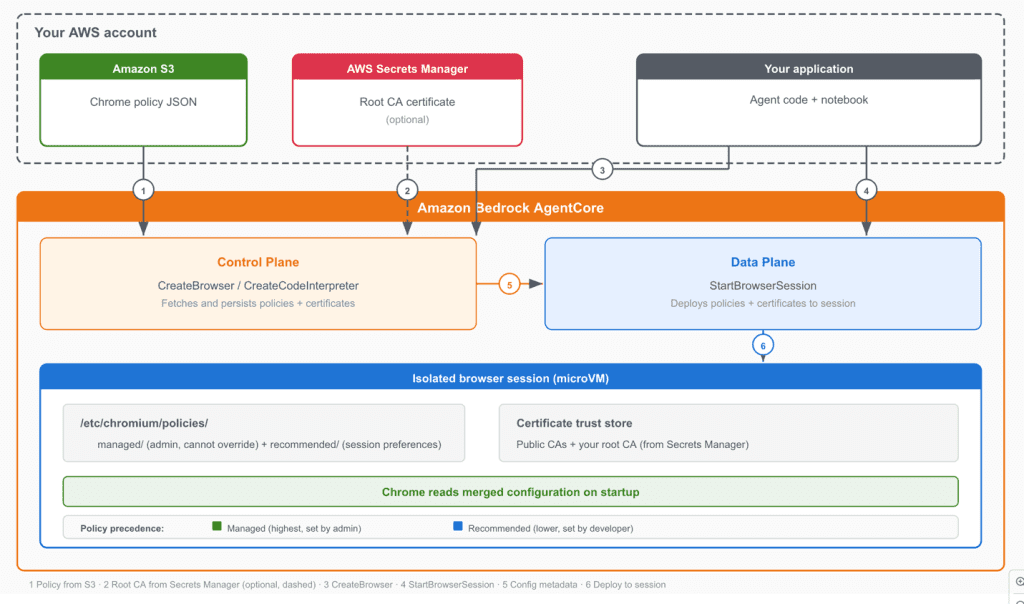
Favorite AI agents with unrestricted web access pose significant security risks. Without Chrome enterprise policies to control browser behavior, an agent might navigate to unauthorized domains, store credentials in the browser’s password manager, or download files outside approved workflows. Organizations with internal services that use a private certificate authority (CA)
Read More
Shared by AWS Machine Learning May 14, 2026
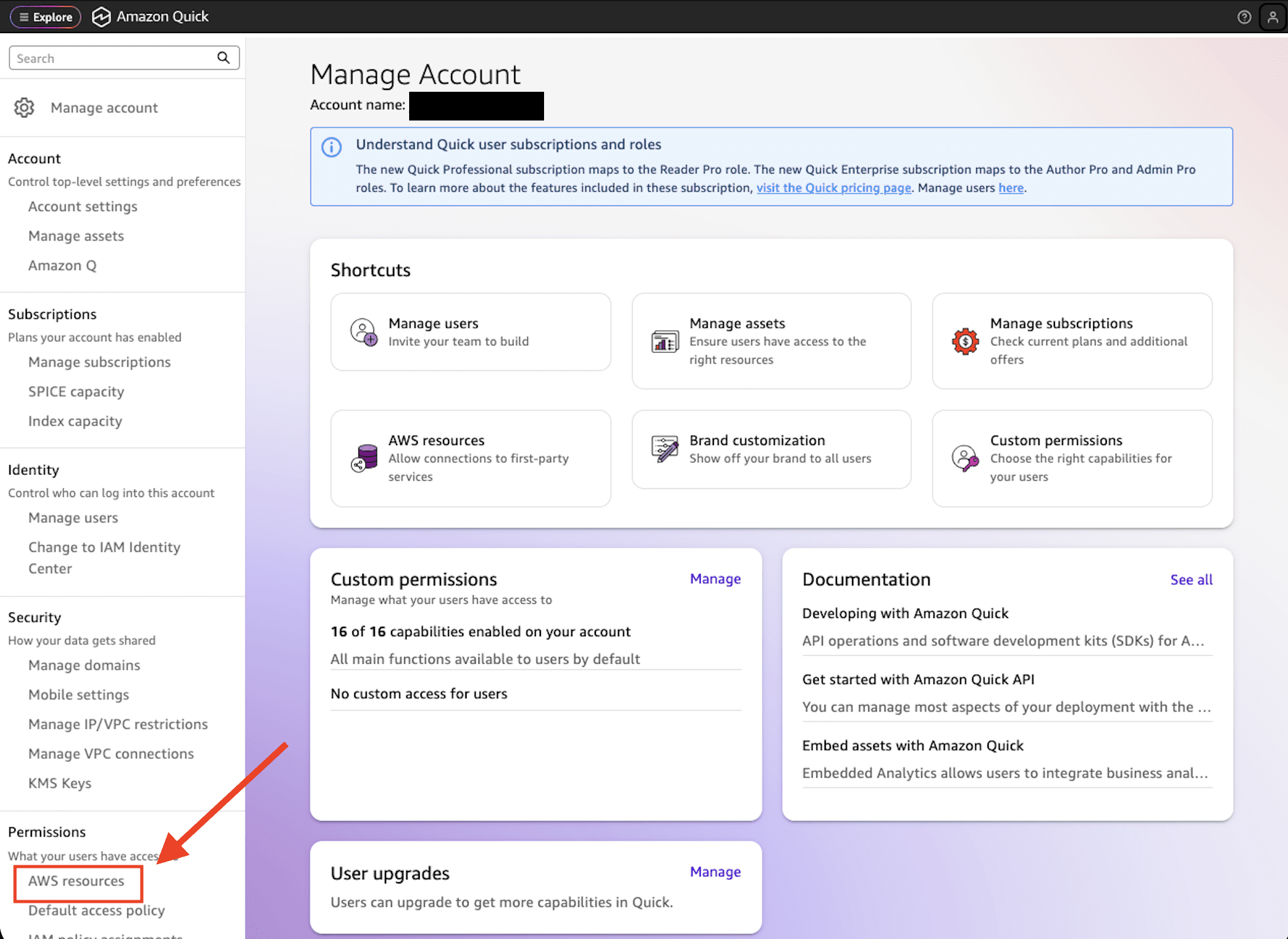
Favorite Amazon Quick is an AI-powered unified intelligence service that brings together an organization’s data, structured data and unstructured enterprise content like documents, emails, and knowledge bases into a single service where anyone can explore, analyze, and take action. With over 40 application integrations, Quick bridges the last-mile gap between
Read More
Shared by AWS Machine Learning May 14, 2026
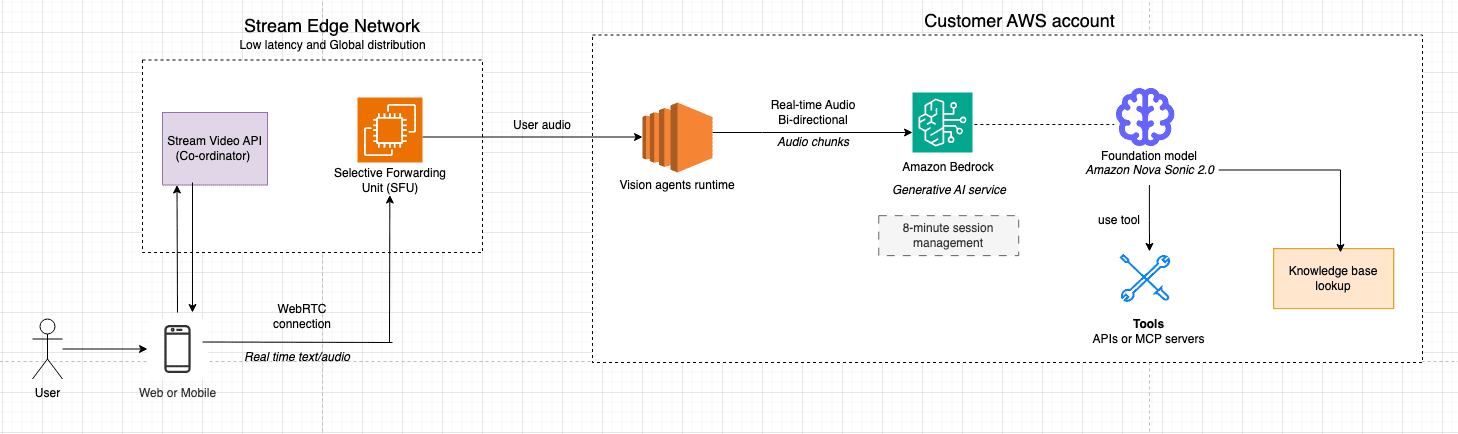
Favorite This post was co-authored with Neevash Ramdial, Technical Marketing leader at Stream Building production-grade voice agents that feel natural and responsive is a complex engineering challenge. You must orchestrate speech-to-speech models, manage low-latency audio streaming, and handle connection lifecycle. You also need to deliver consistent experiences across web, mobile,
Read More
Shared by AWS Machine Learning May 14, 2026
Favorite Improving bot accuracy in Amazon Lex starts with handling how customers communicate naturally. Your customers express the same request in dozens of different ways, combine multiple pieces of information in one sentence, and often speak ambiguously. The Assisted NLU (natural language understanding) feature in Amazon Lex helps you improve
Read More
Shared by AWS Machine Learning May 14, 2026
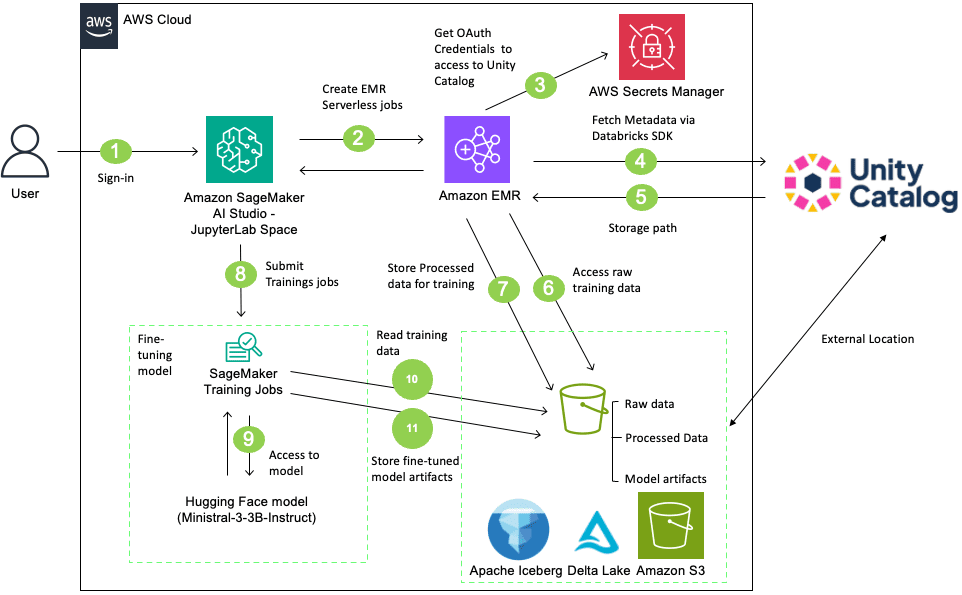
Favorite When you fine-tune large language models (LLMs) with Amazon SageMaker AI while using Databricks Unity Catalog, you might face unique challenges like how to maintain strict data governance while using best-in-class machine learning (ML) services. Unity Catalog governs metadata and permissions, while the underlying data resides in Amazon Simple
Read More
Shared by AWS Machine Learning May 13, 2026
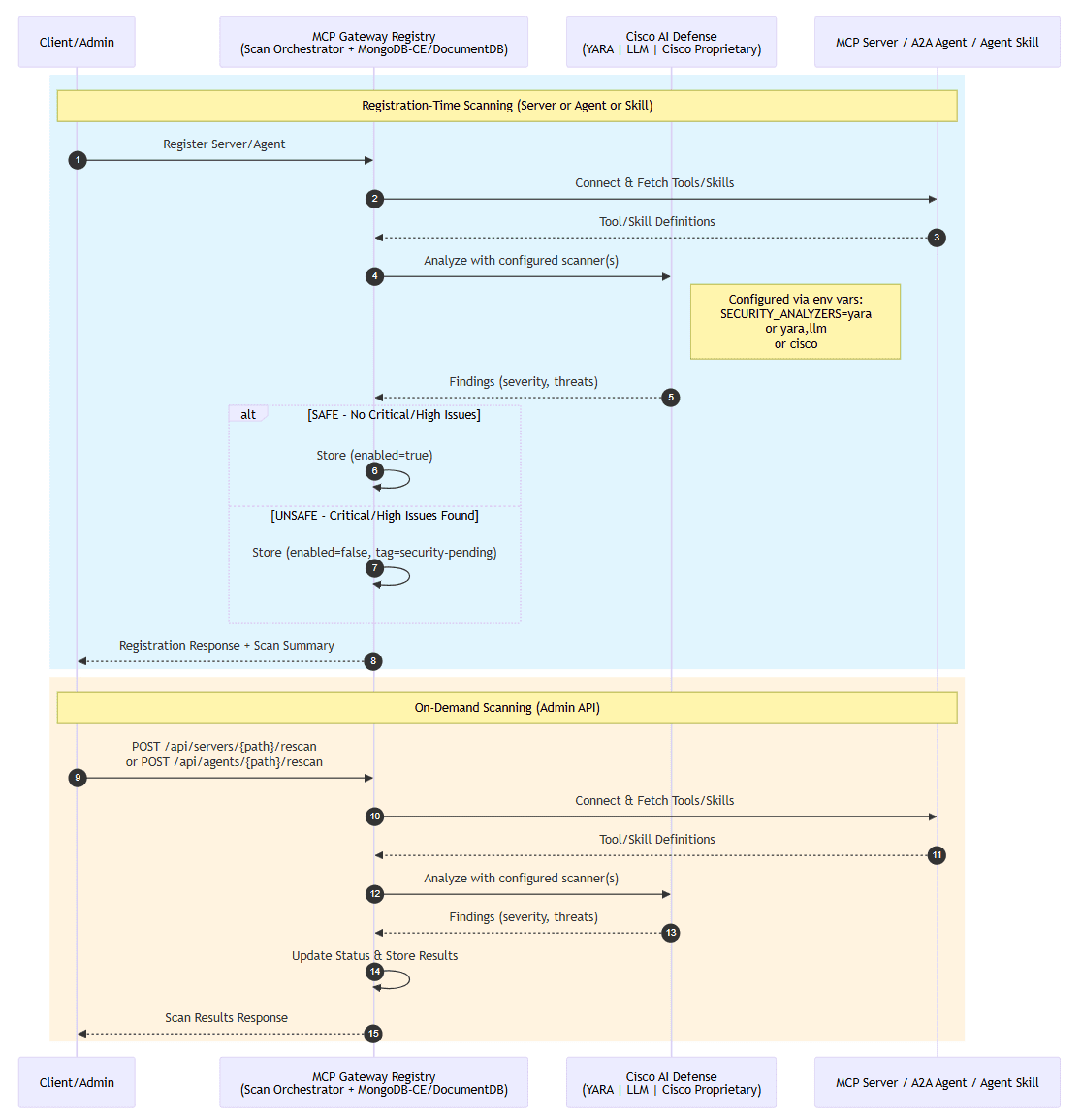
Favorite Model Context Protocol (MCP) adoption has accelerated rapidly since its introduction in November 2024. Enterprises now manage dozens to hundreds of MCP servers—tools that extend AI agent capabilities by connecting them to external data sources and APIs. The Agent-to-Agent (A2A) Protocol followed in April 2025, enabling autonomous agents to
Read More
Shared by AWS Machine Learning May 13, 2026
Favorite Building end-to-end live streaming applications with real-time voice interaction presents several challenges: network bandwidth constraints can cause high latency and quality degradation in time-critical applications. Language barriers limit effective human-machine interaction in multilingual voice communication. Scalability and resilience require a difficult balance between performance and infrastructure costs. Cross-browser and
Read More
Shared by AWS Machine Learning May 13, 2026