Favorite It’s easy to distinguish a lake from a flood. But when you’re looking at an aerial photograph, factors like angle, altitude, cloud cover, and context can make the task more difficult. And when you need to identify 100,000 aerial images in order to give first responders the information they
Read More
 Shared by AWS Machine Learning December 18, 2020
Shared by AWS Machine Learning December 18, 2020
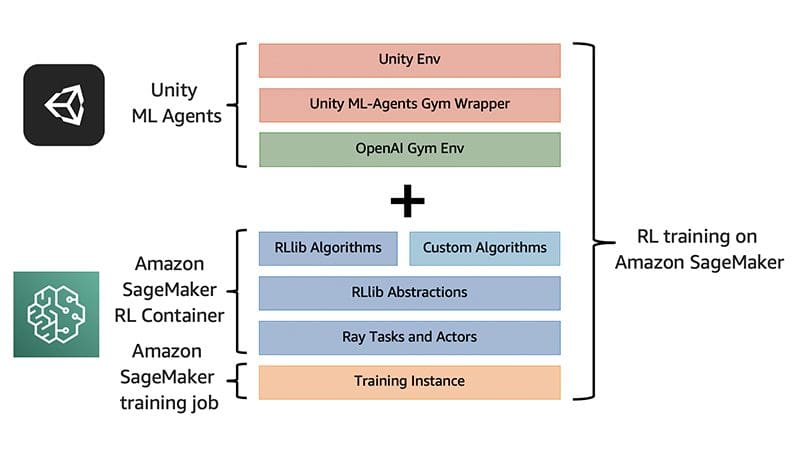
Favorite Unity is one of the most popular game engines that has been adopted not only for video game development but also by industries such as film and automotive. Unity offers tools to create virtual simulated environments with customizable physics, landscapes, and characters. The Unity Machine Learning Agents Toolkit (ML-Agents)
Read More
Shared by AWS Machine Learning December 17, 2020
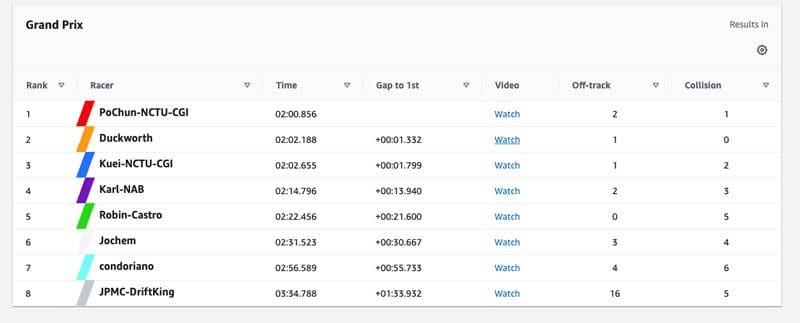
Favorite AWS DeepRacer is the fastest way to get rolling with machine learning (ML). It’s a fully autonomous 1/18th scale race car driven by reinforcement learning, a 3D racing simulator, and a global racing league. Throughout 2020, tens of thousands of developers honed their ML skills and competed in the
Read More
Shared by AWS Machine Learning December 16, 2020
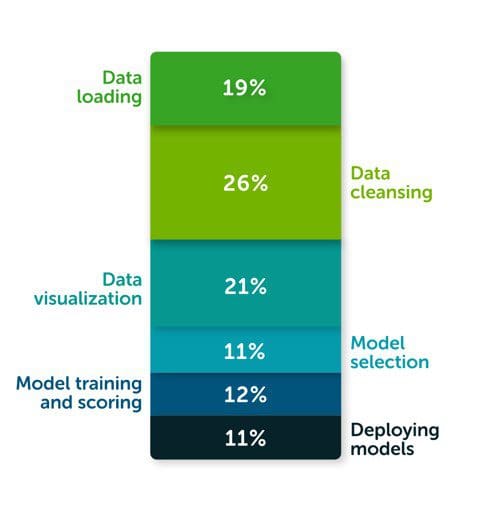
Favorite According to The State of Data Science 2020 survey, data management, exploratory data analysis (EDA), feature selection, and feature engineering accounts for more than 66% of a data scientist’s time (see the following diagram). The same survey highlights that the top three biggest roadblocks to deploying a model in
Read More
Shared by AWS Machine Learning December 12, 2020
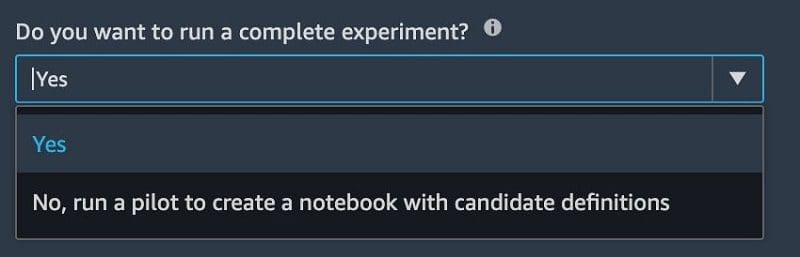
Favorite Amazon SageMaker Autopilot automatically trains and tunes the best machine learning (ML) models for classification or regression problems while allowing you to maintain full control and visibility. This not only allows data analysts, developers, and data scientists to train, tune, and deploy models with little to no code, but
Read More
Shared by AWS Machine Learning December 11, 2020
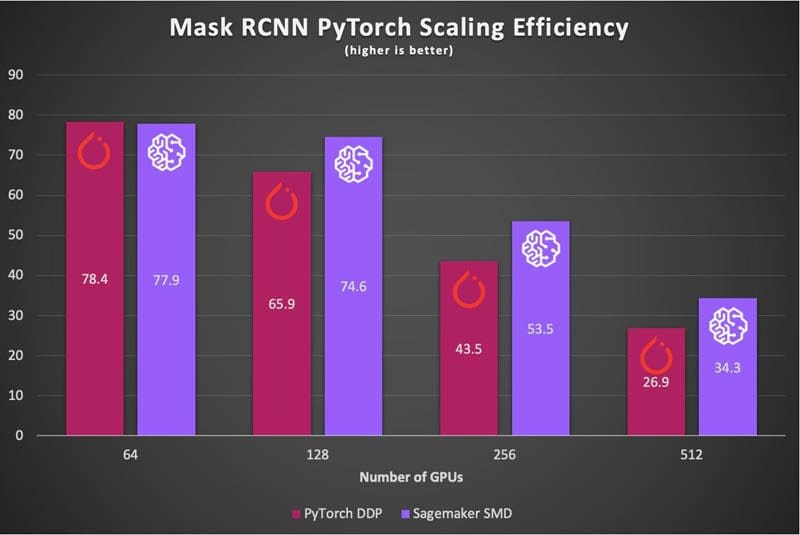
Favorite Note: At the AWS re:Invent Machine Learning Keynote we announced performance records for T5-3B and Mask-RCNN. This blog post includes updated numbers with additional optimizations since the keynote aired live on 12/8. At re:Invent 2019, we demonstrated the fastest training times on the cloud for Mask R-CNN, a popular
Read More
Shared by AWS Machine Learning December 11, 2020
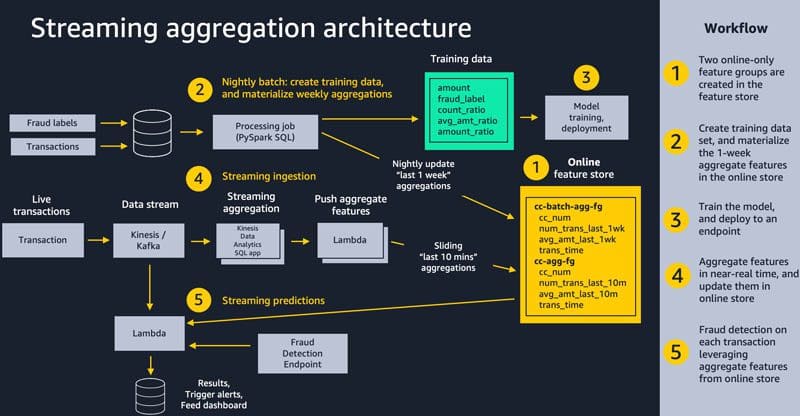
Favorite Businesses are increasingly using machine learning (ML) to make near-real time decisions, such as placing an ad, assigning a driver, recommending a product, or even dynamically pricing products and services. ML models make predictions given a set of input data known as features, and data scientists easily spend more
Read More
Shared by AWS Machine Learning December 11, 2020
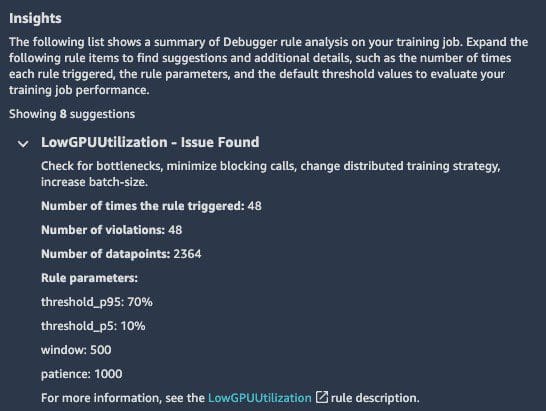
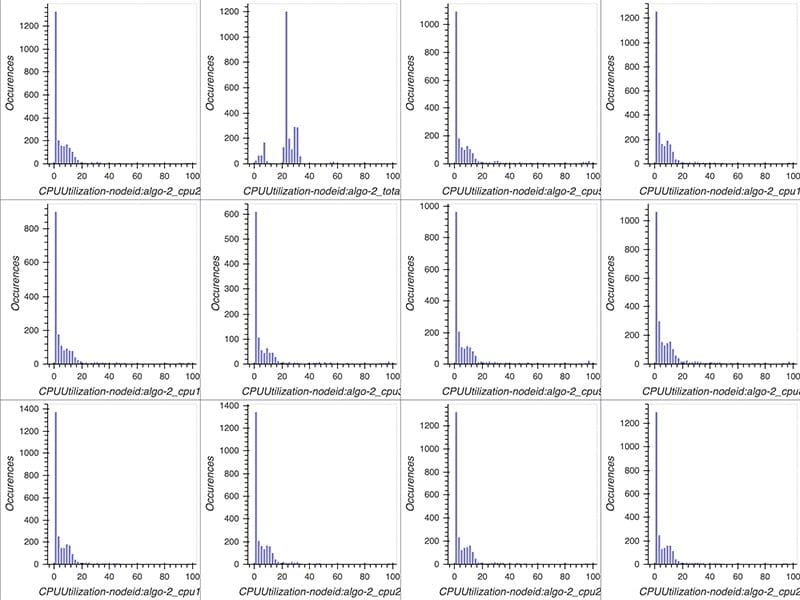
Favorite At AWS re:Invent 2020, AWS released the profiling functionality for Amazon SageMaker Debugger. In this post, we expand on the importance of profiling deep neural network (DNN) training, review some of the common performance bottlenecks you might encounter, and demonstrate how to use the profiling feature in Debugger to
Read More
Shared by AWS Machine Learning December 11, 2020
Favorite Machine learning (ML) has shown great promise across domains such as predictive analysis, speech processing, image recognition, recommendation systems, bioinformatics, and more. Training ML models is a time- and compute-intensive process, requiring multiple training runs with different hyperparameters before a model yields acceptable accuracy. CPU- and GPU-based distributed training
Read More
Shared by AWS Machine Learning December 10, 2020
Favorite We’re excited to announce Amazon HealthLake, a new HIPAA-eligible service for healthcare providers, health insurance companies, and pharmaceutical companies to securely store, transform, query, analyze, and share health data in the cloud, at petabyte scale. HealthLake uses machine learning (ML) models trained to automatically understand and extract meaningful medical
Read More
Shared by AWS Machine Learning December 10, 2020