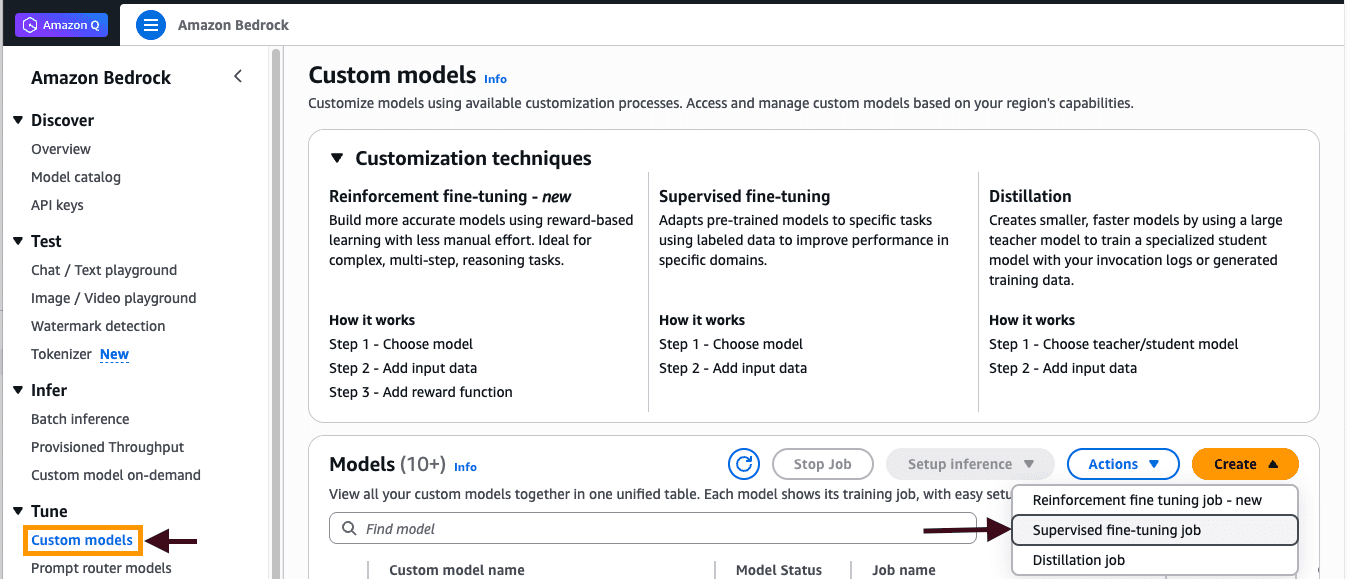
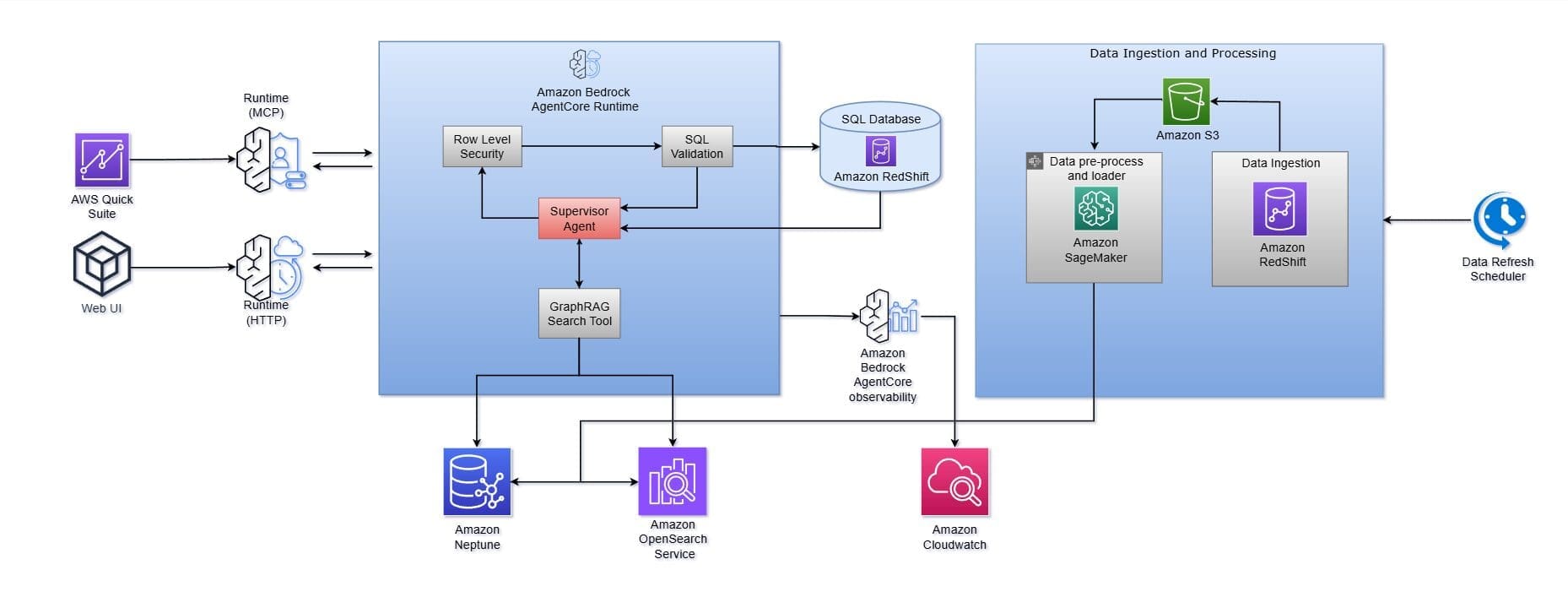
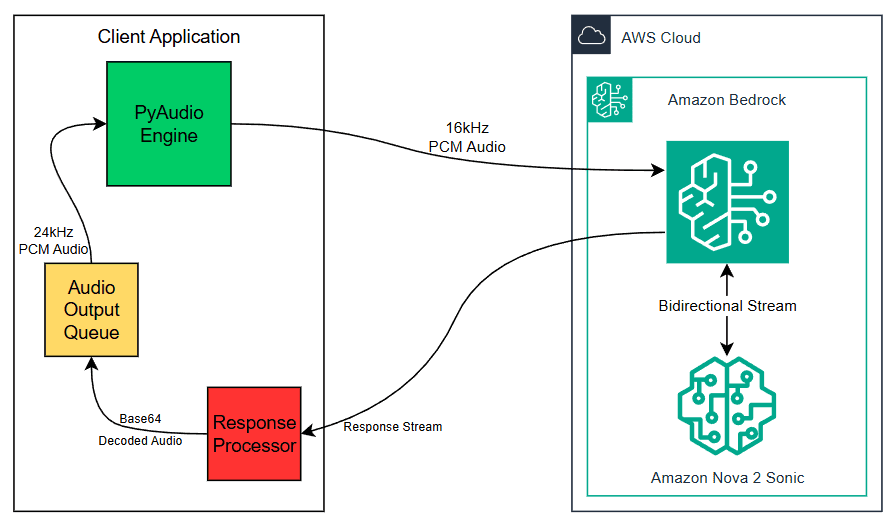
Embed a live AI browser agent in your React app with Amazon Bedrock AgentCore
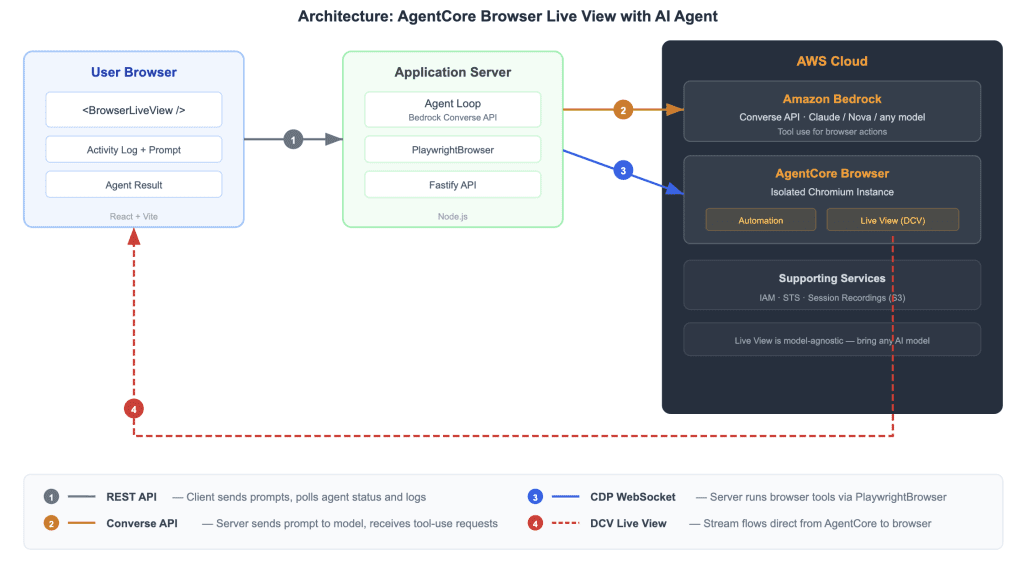
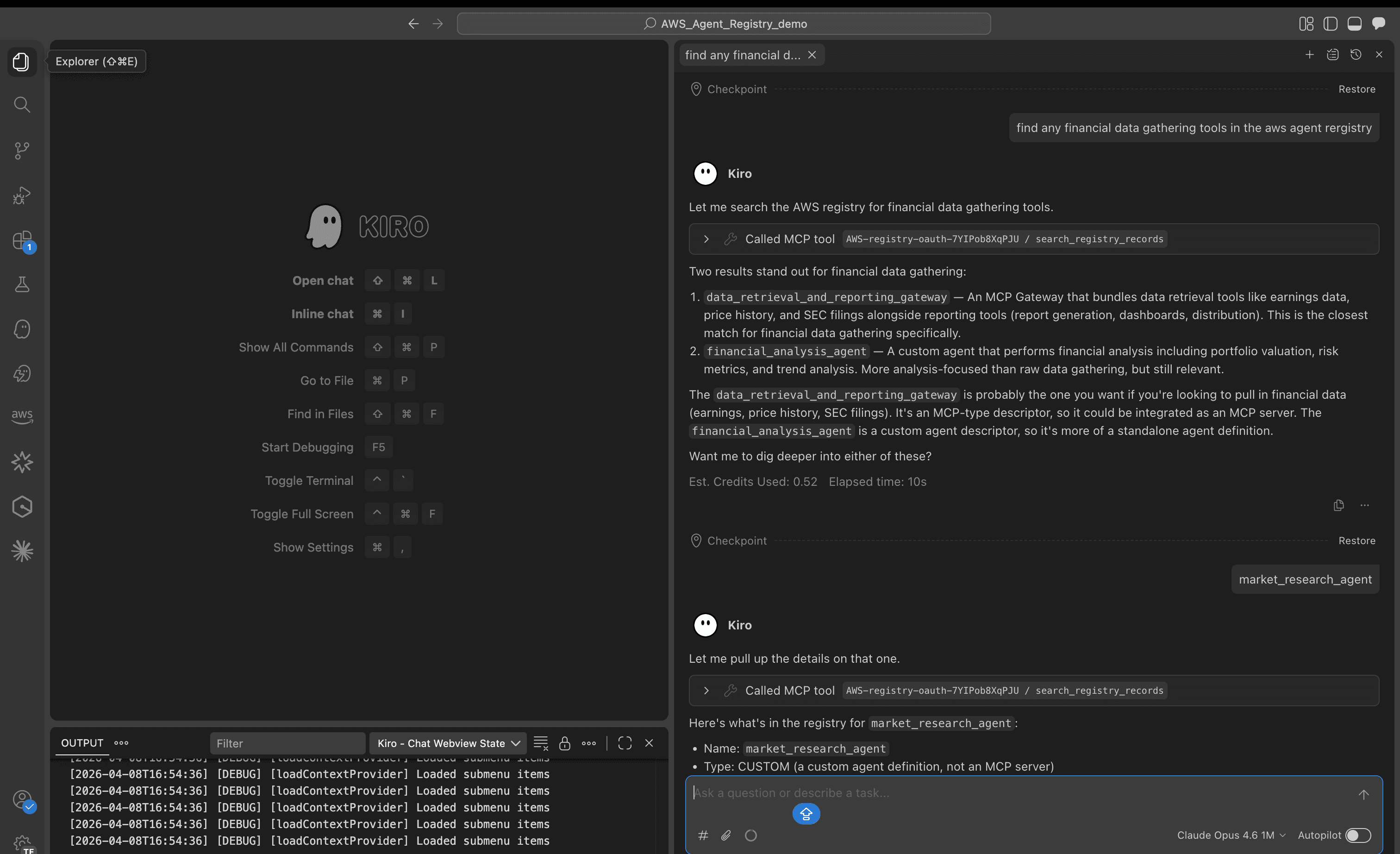
Favorite When you build AI-powered applications, your users must understand and trust AI agents that navigate websites and interact with web content on their behalf. When an agent interacts with web content autonomously, your users require visibility into those actions to maintain confidence and control, which they don’t currently have.
Read More![]() Shared by AWS Machine Learning April 9, 2026
Shared by AWS Machine Learning April 9, 2026