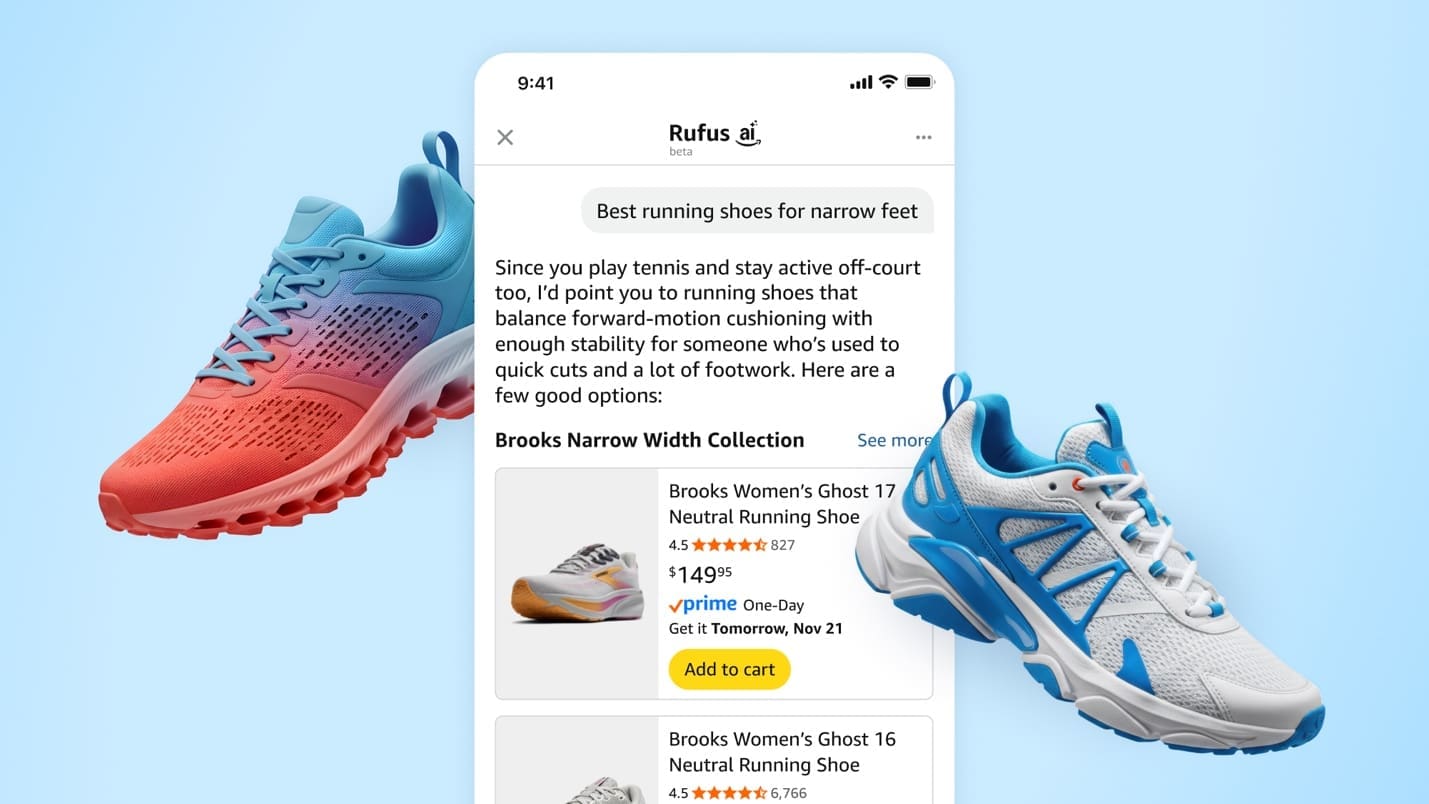
Favorite Our team at Amazon builds Rufus, an AI-powered shopping assistant which delivers intelligent, conversational experiences to delight our customers. More than 250 million customers have used Rufus this year. Monthly users are up 140% YoY and interactions are up 210% YoY. Additionally, customers that use Rufus during a shopping
Read More
 Shared by AWS Machine Learning November 20, 2025
Shared by AWS Machine Learning November 20, 2025
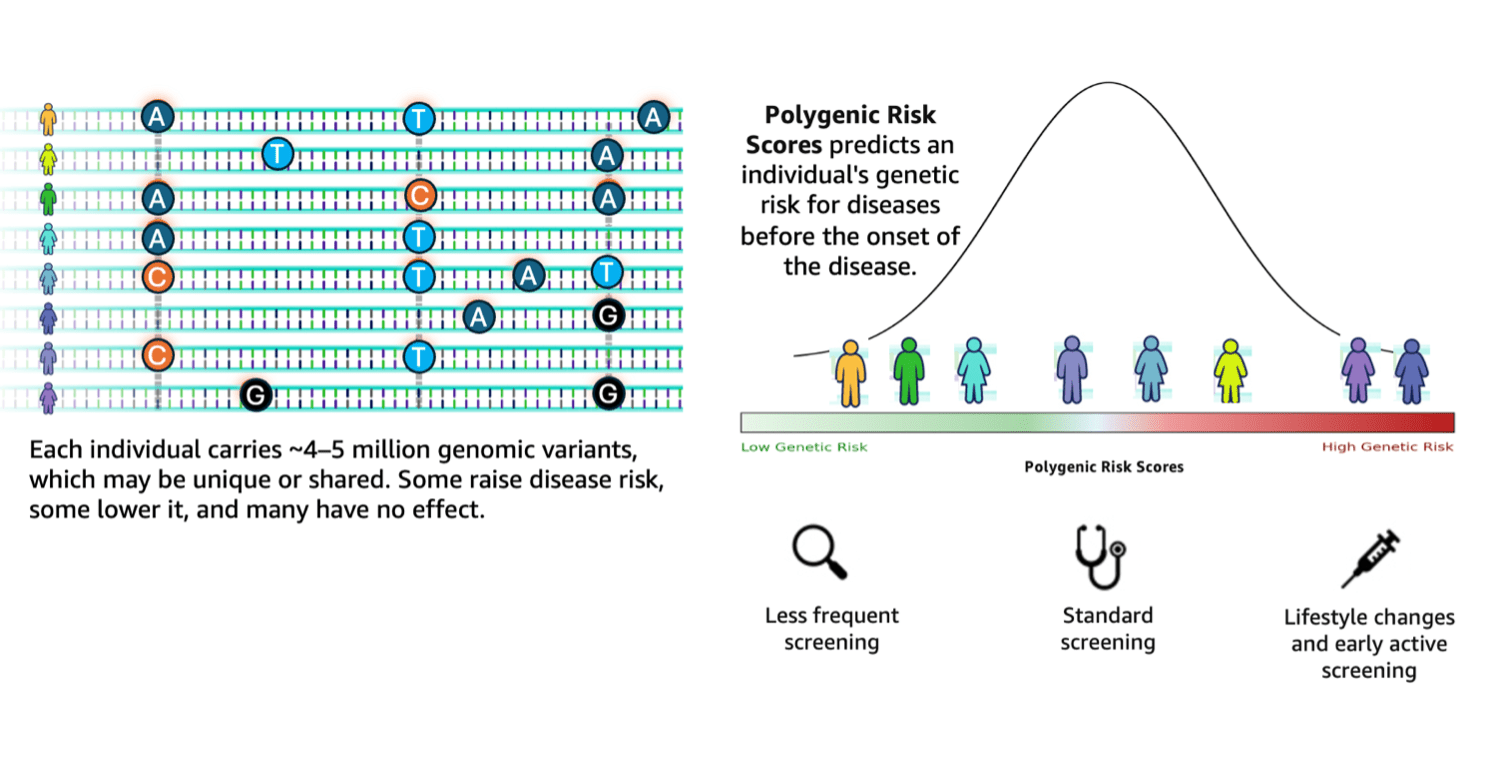
Favorite Genomic research stands at a transformative crossroads where the exponential growth of sequencing data demands equally sophisticated analytical capabilities. According to the 1000 Genomes Project, a typical human genome differs from the reference at 4.1–5.0 million sites, with most variants being SNPs and short indels. These variants, when aggregated
Read More
Shared by AWS Machine Learning November 20, 2025
Favorite This post is co-written with Hossein Salami and Jwalant Vyas from MSD. In the biopharmaceutical industry, deviations in the manufacturing process are rigorously addressed. Each deviation is thoroughly documented, and its various aspects and potential impacts are closely examined to help ensure drug product quality, patient safety, and compliance.
Read More
Shared by AWS Machine Learning November 20, 2025
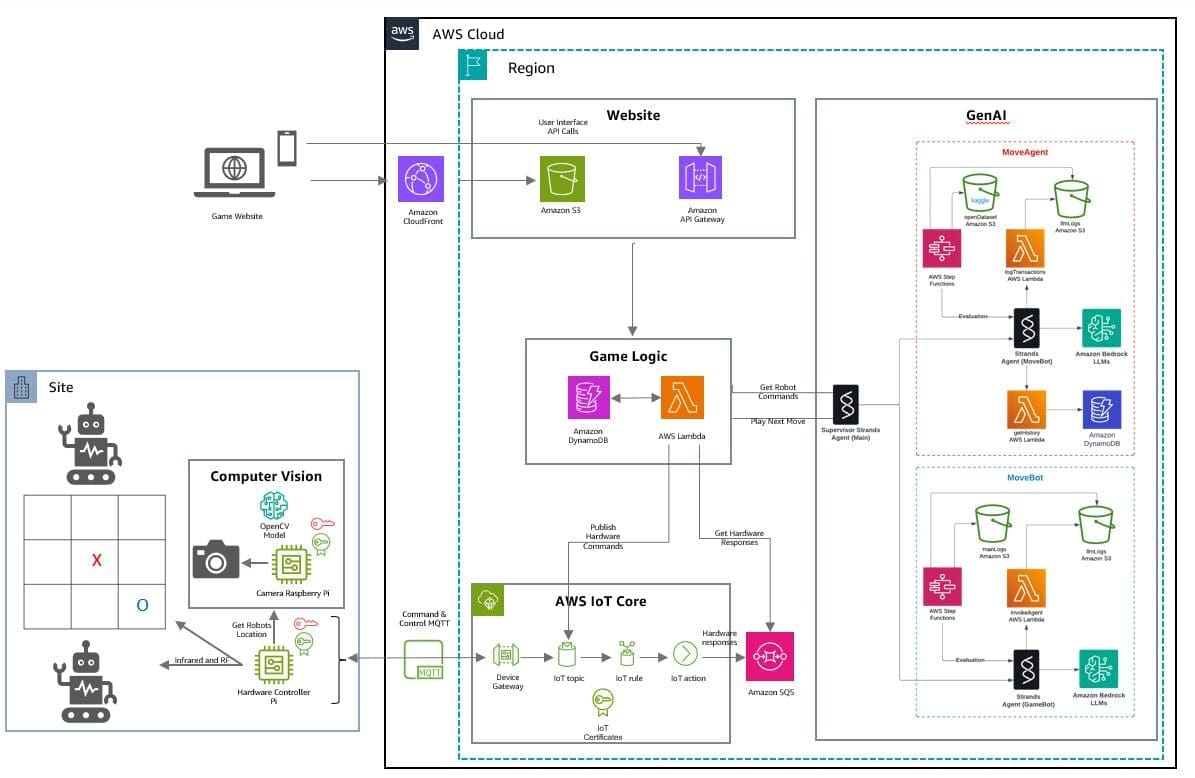
Favorite Large language models (LLMs) now support a wide range of use cases, from content summarization to the ability to reason about complex tasks. One exciting new topic is taking generative AI to the physical world by applying it to robotics and physical hardware. Inspired by this, we developed a
Read More
Shared by AWS Machine Learning November 19, 2025
Favorite Optimizing generative AI applications relies on tailoring foundation models (FMs) using techniques such as prompt engineering, RAG, continued pre-training, and fine-tuning. Efficient fine-tuning is achieved by strategically managing hardware, training time, data volume, and model quality to reduce resource demands and maximize value. Spectrum is a new approach designed
Read More
Shared by AWS Machine Learning November 19, 2025
Favorite This post was written with Bharath Suresh and Mary Law from Snowflake. Agentic AI is a type of AI that functions autonomously, automating a broader range of tasks with minimal supervision. It combines traditional AI and generative AI capabilities to make decisions, perform tasks, and adapt to its environment
Read More
Shared by AWS Machine Learning November 19, 2025
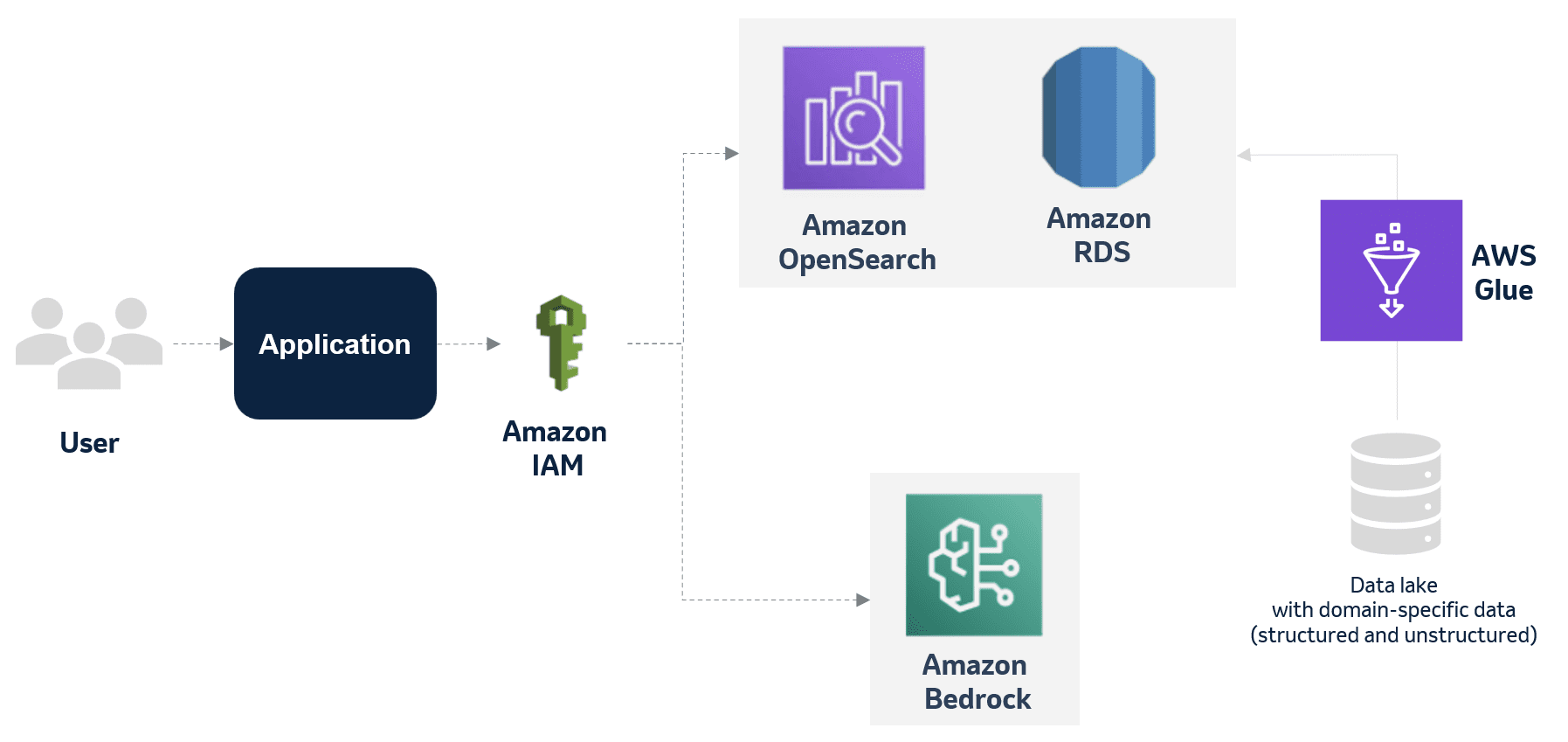
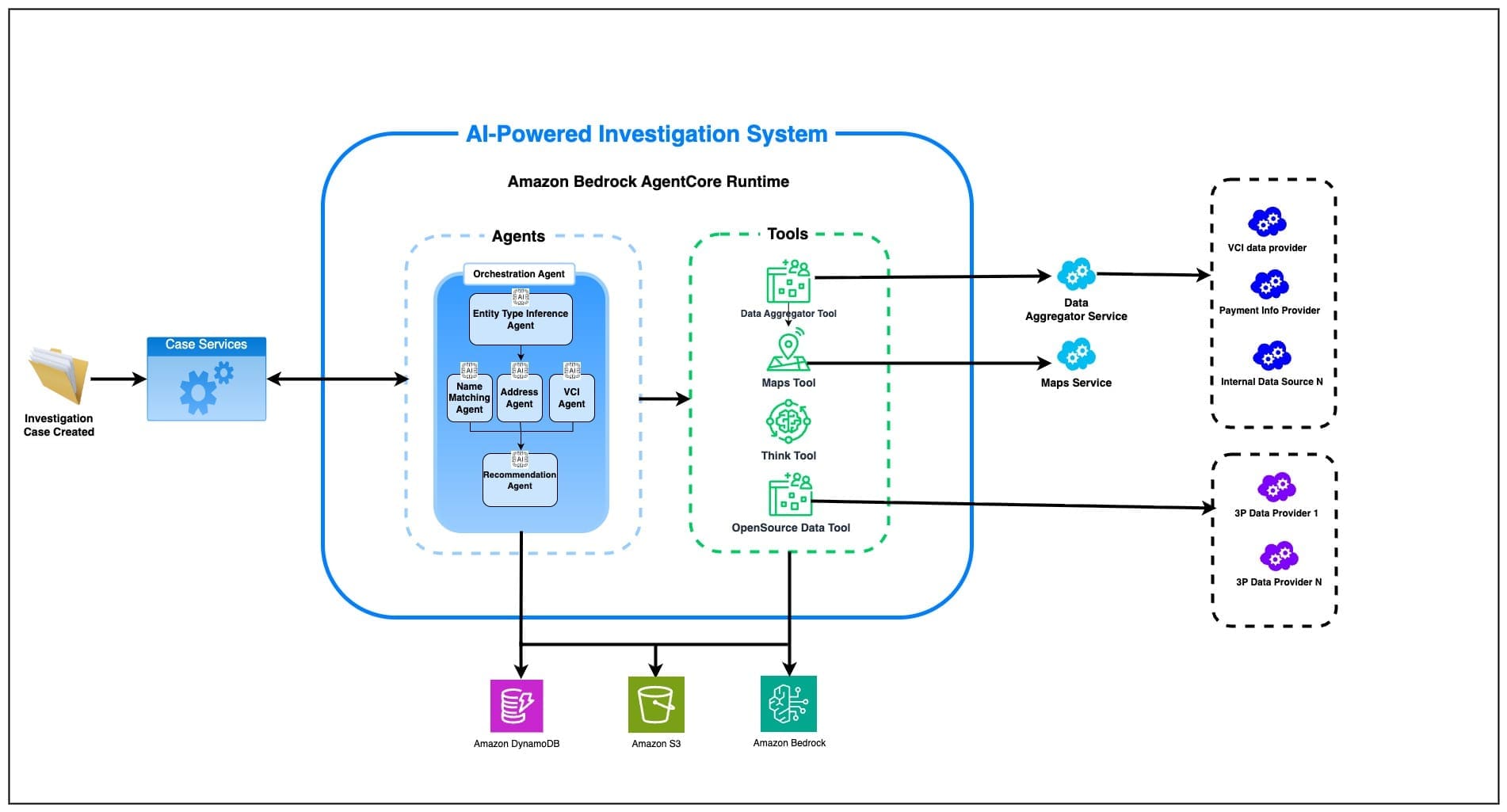
Favorite At Amazon, we screen customers and transactions across our global business and its subsidiaries to comply with sanctions and other global laws. Failure to comply with these laws can result in severe financial penalties and reputational harm. Amazon’s Compliance team has developed an AI-driven screening and investigations system that
Read More
Shared by AWS Machine Learning November 19, 2025
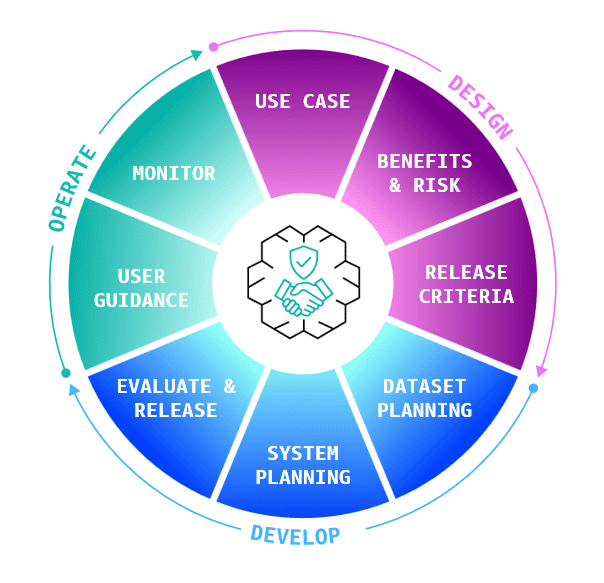
Favorite As AI applications grow more complex, many builders struggle to appropriately and responsibly balance AI benefits and risks. Few resources exist that help non-experts articulate and resolve the key design decisions they must make. However, it doesn’t have to be this way. Today, we’re announcing the AWS Well-Architected Responsible
Read More
Shared by AWS Machine Learning November 19, 2025
Favorite Over the past two years, I’ve worked with many customers using generative AI to transform their organizations. Most stall at experimentation, because costs stack up and timelines extend before delivering demonstrable value. A 2023 AWS MIT Chief Data Officer (CDO) Symposium survey backs this up, reporting that while 71%
Read More
Shared by AWS Machine Learning November 18, 2025
Favorite Amazon SageMaker HyperPod is a purpose-built infrastructure for optimizing foundation model training and inference at scale. SageMaker HyperPod removes the undifferentiated heavy lifting involved in building and optimizing machine learning (ML) infrastructure for training foundation models (FMs). As AI moves towards deployment adopting to a multitude of domains and
Read More
Shared by AWS Machine Learning November 18, 2025