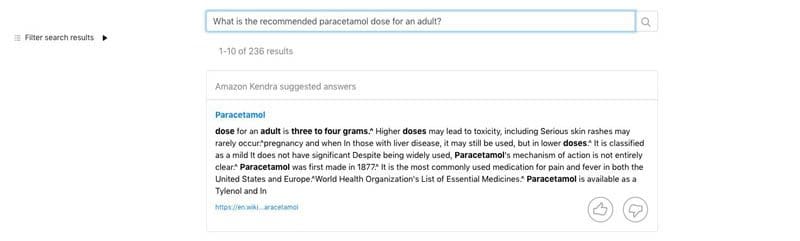
Maximize TensorFlow performance on Amazon SageMaker endpoints for real-time inference
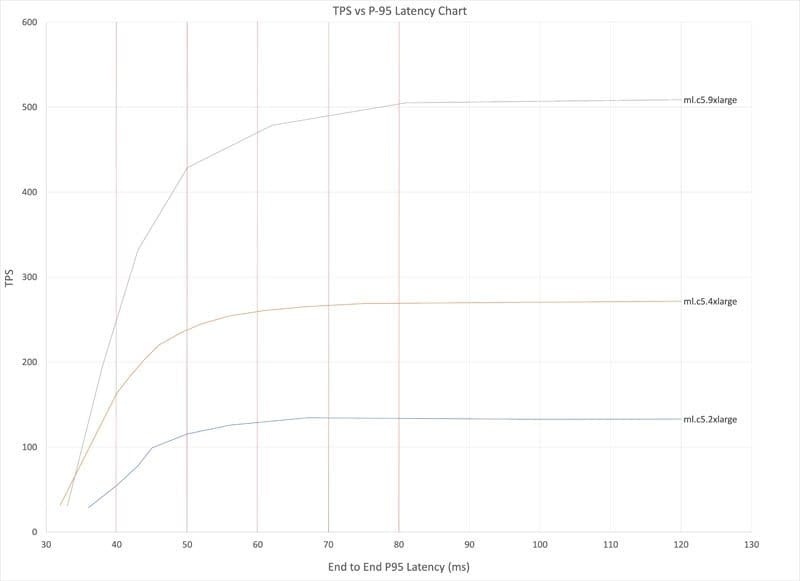
Favorite Machine learning (ML) is realized in inference. The business problem you want your ML model to solve is the inferences or predictions that you want your model to generate. Deployment is the stage in which a model, after being trained, is ready to accept inference requests. In this post,
Read More![]() Shared by AWS Machine Learning May 14, 2021
Shared by AWS Machine Learning May 14, 2021