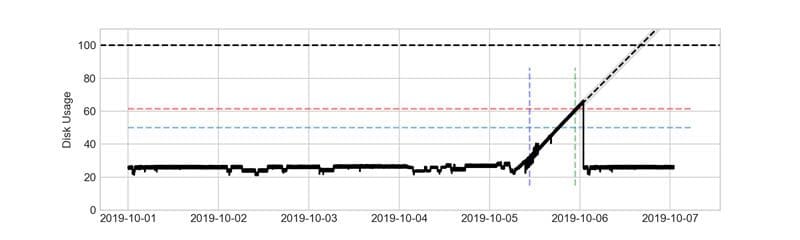
Anomaly detection with Amazon Lookout for Metrics
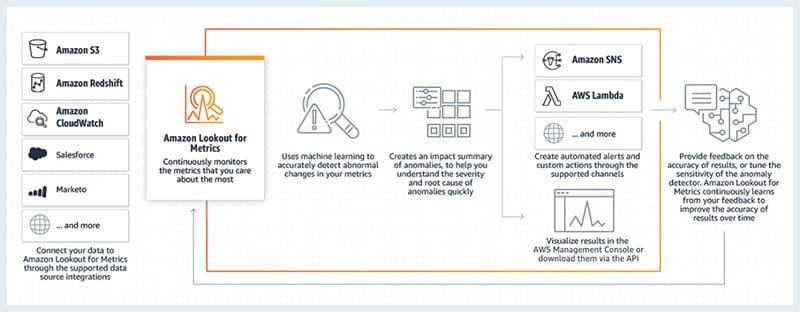
Favorite This is a guest blog post from Quantiphi, an AWS Advanced Consulting Partner that specializes in artificial intelligence, machine learning, and data and analytics solutions. We’ve all heard the saying “time is money,” and that’s especially true for the retail industry. In a highly competitive environment where large volumes
Read More![]() Shared by AWS Machine Learning February 5, 2021
Shared by AWS Machine Learning February 5, 2021