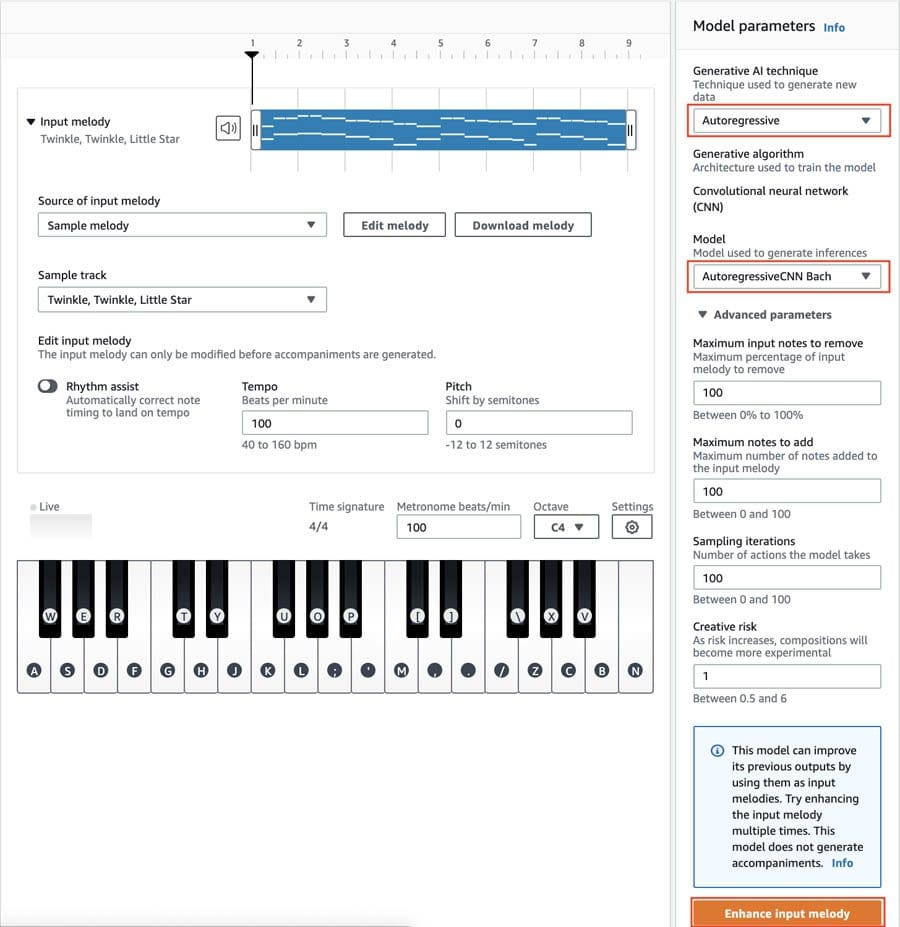
Favorite We are back with a spooktacular AWS DeepComposer Chartbusters challenge, Track or Treat! In this challenge, you can interactively collaborate with the ghost in the machine (learning) and compose spooky music! Chartbusters is a global monthly challenge where you can use AWS DeepComposer to create original compositions on the
Read More
 Shared by AWS Machine Learning October 2, 2020
Shared by AWS Machine Learning October 2, 2020
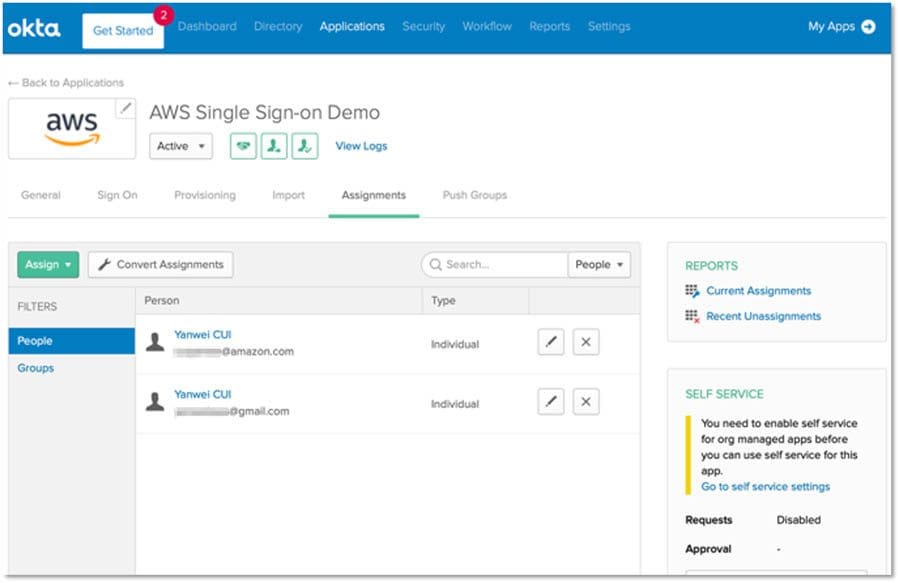
Favorite In 2019, AWS announced Amazon SageMaker Studio, a unified integrated development environment (IDE) for machine learning (ML) development. You can write code, track experiments, visualize data, and perform debugging and monitoring within a single, integrated visual interface. Amazon SageMaker Studio supports a single sign-on experience with AWS Single Sign-On
Read More
Shared by AWS Machine Learning October 2, 2020
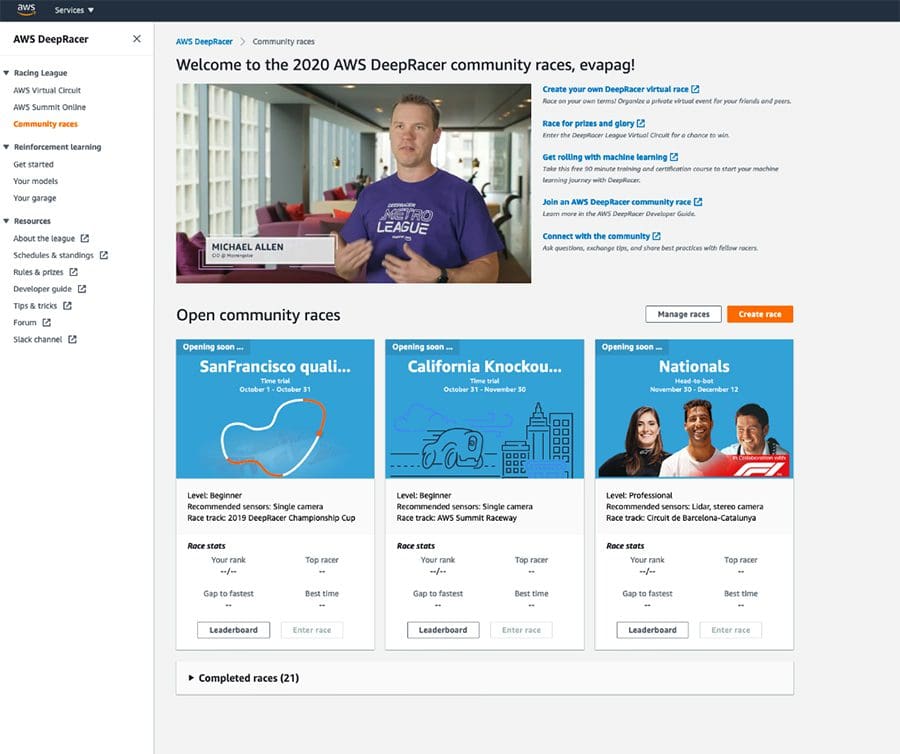
Favorite AWS DeepRacer allows you to get hands-on with machine learning (ML) through a fully autonomous 1/18th scale race car driven by reinforcement learning, a 3D racing simulator on the AWS DeepRacer console, a global racing league, and hundreds of customer-initiated community races. With AWS DeepRacer community races, you can
Read More
Shared by AWS Machine Learning October 2, 2020
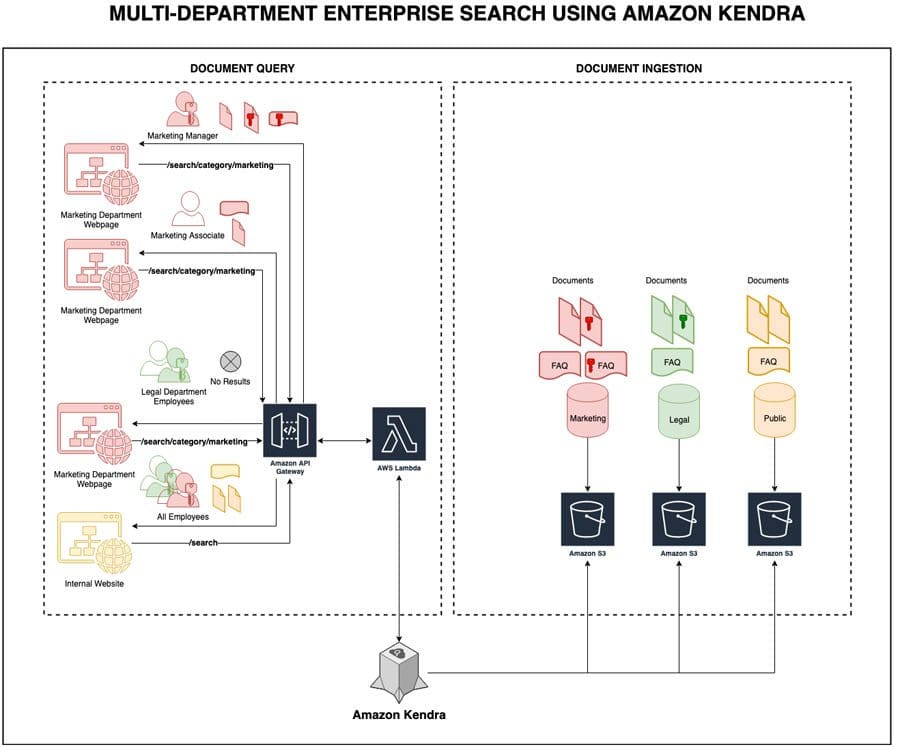
Favorite An enterprise typically houses multiple departments such as engineering, finance, legal, and marketing, creating a growing number of documents and content that employees need to access. Creating a search experience that intuitively delivers the right information according to an employee’s role, and the department is critical to driving productivity
Read More
Shared by AWS Machine Learning October 2, 2020
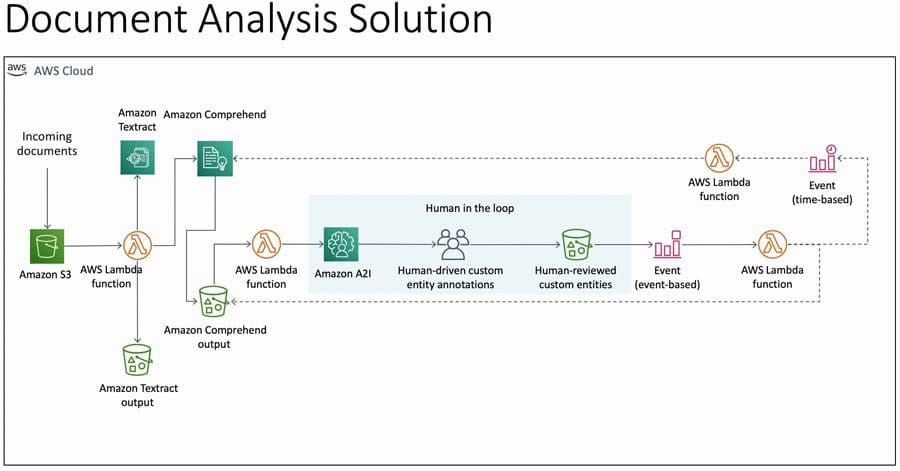
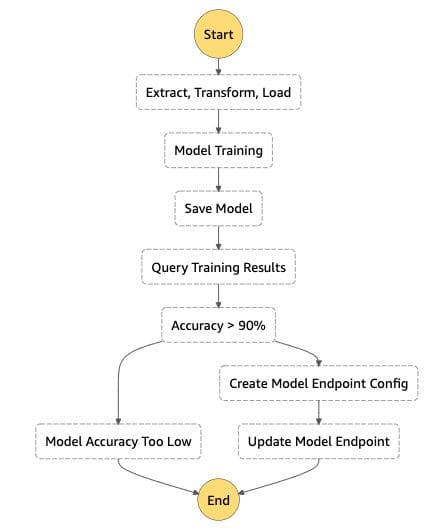
Favorite As organizations grow larger in size, so does the need for having better document processing. In industries such as healthcare, legal, insurance, and banking, the continuous influx of paper-based or PDF documents (like invoices, health charts, and insurance claims) have pushed businesses to consider evolving their document processing capabilities.
Read More
Shared by AWS Machine Learning October 2, 2020
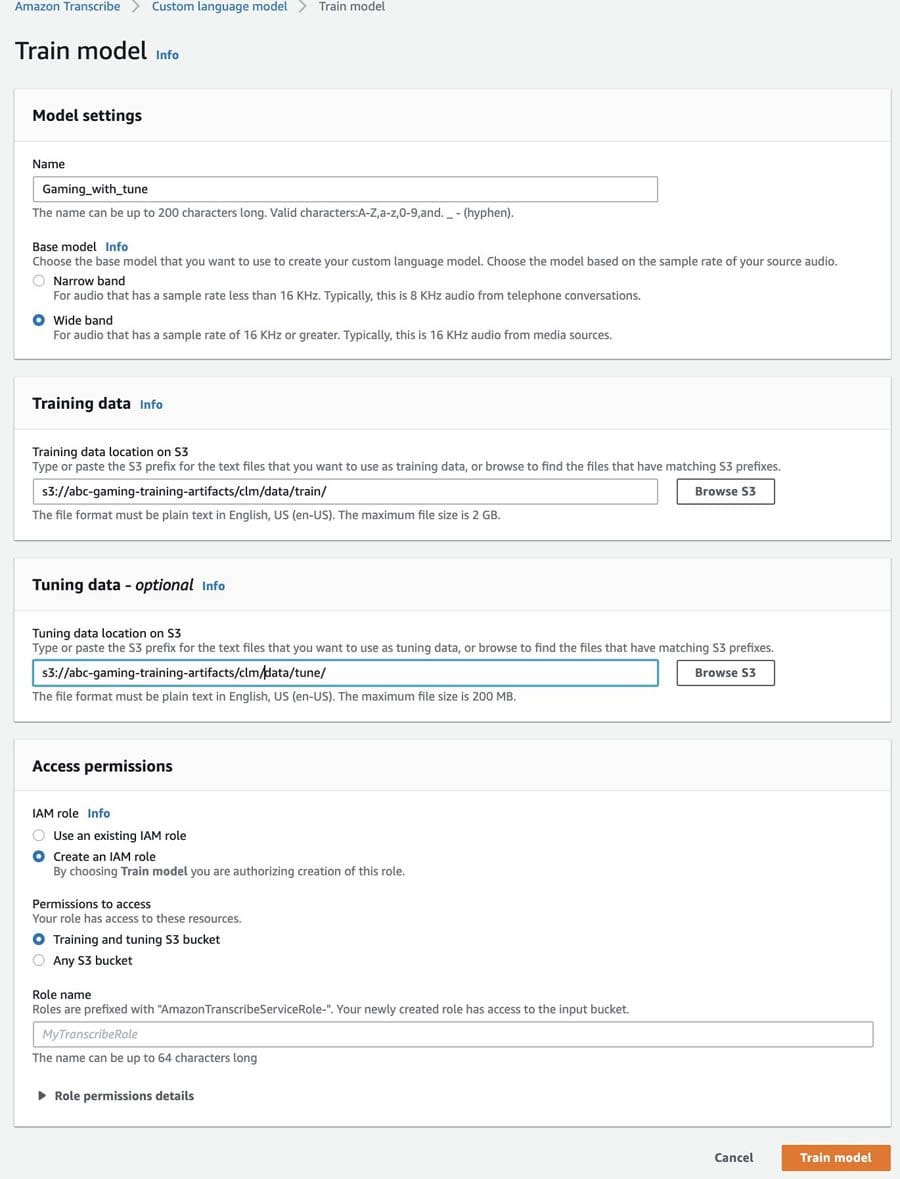
Favorite Amazon Transcribe is a fully-managed automatic speech recognition service (ASR) that makes it easy to add speech-to-text capabilities to voice-enabled applications. As our service grows, so does the diversity of our customer base, which now spans domains such as insurance, finance, law, real estate, media, hospitality, and more. Naturally,
Read More
Shared by AWS Machine Learning October 1, 2020
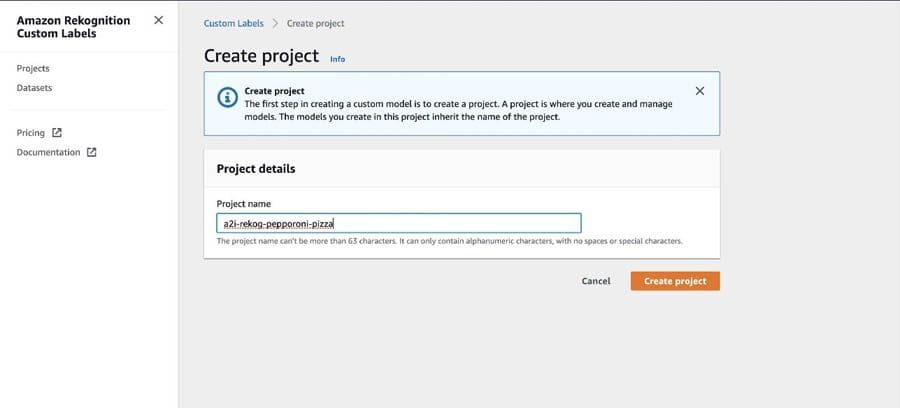
Favorite Customers need machine learning (ML) models to detect objects that are interesting for their business. In most cases doing so is hard as these models needs thousands of labelled images and deep learning expertise. Generating this data can take months to gather, and can require large teams of labelers
Read More
Shared by AWS Machine Learning October 1, 2020
Favorite Every day there is something new going on in the world of AWS Machine Learning—from launches to new use cases to interactive trainings. We’re packaging some of the not-to-miss information from the ML Blog and beyond for easy perusing each month. Check back at the end of each month
Read More
Shared by AWS Machine Learning October 1, 2020
Favorite Apache Spark is a unified analytics engine for large scale, distributed data processing. Typically, businesses with Spark-based workloads on AWS use their own stack built on top of Amazon Elastic Compute Cloud (Amazon EC2), or Amazon EMR to run and scale Apache Spark, Hive, Presto, and other big data
Read More
Shared by AWS Machine Learning September 30, 2020
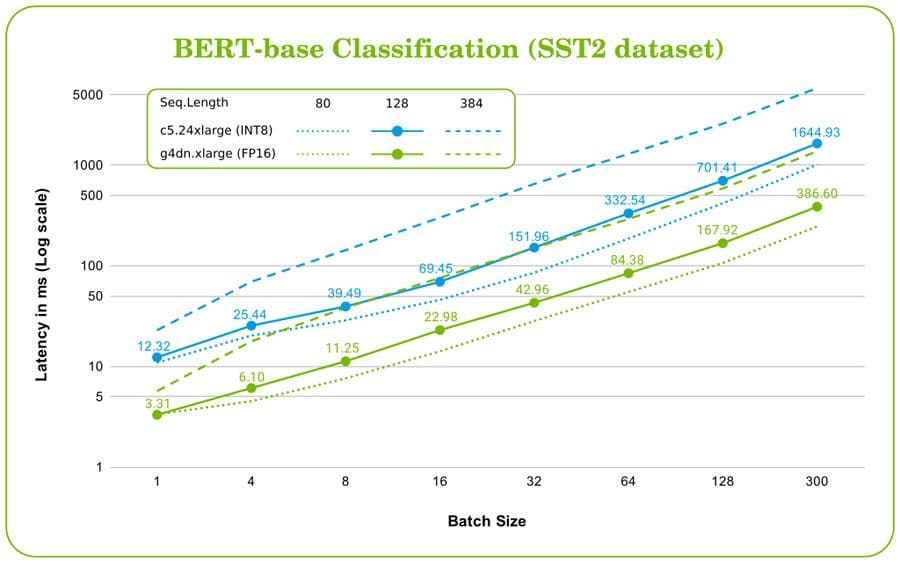
Favorite Bidirectional Encoder Representations from Transformers (BERT) [1] has become one of the most popular models for natural language processing (NLP) applications. BERT can outperform other models in several NLP tasks, including question answering and sentence classification. Training the BERT model on large datasets is expensive and time consuming, and
Read More
Shared by AWS Machine Learning September 29, 2020