Automate video insights for contextual advertising using Amazon Bedrock Data Automation
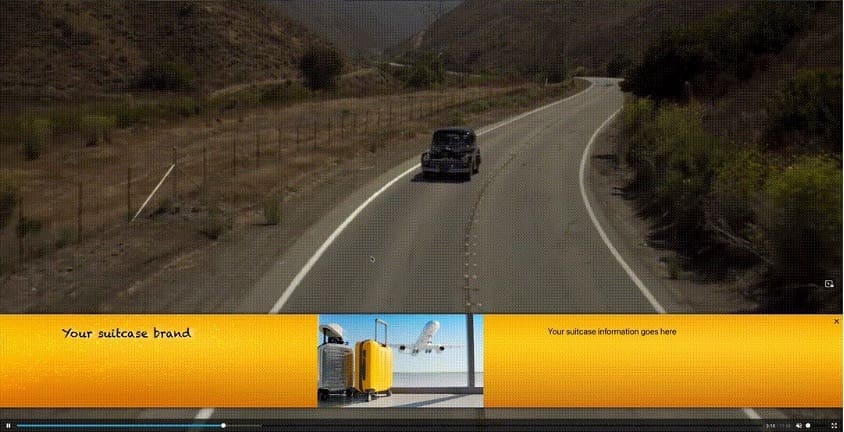
Favorite Contextual advertising, a strategy that matches ads with relevant digital content, has transformed digital marketing by delivering personalized experiences to viewers. However, implementing this approach for streaming video-on-demand (VOD) content poses significant challenges, particularly in ad placement and relevance. Traditional methods rely heavily on manual content analysis. For example,
Read More![]() Shared by AWS Machine Learning April 18, 2025
Shared by AWS Machine Learning April 18, 2025