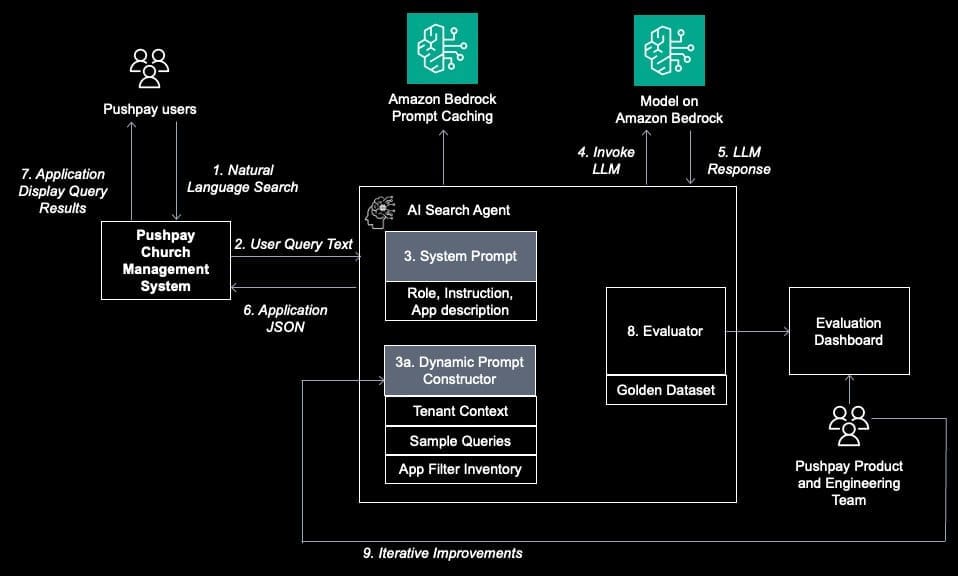
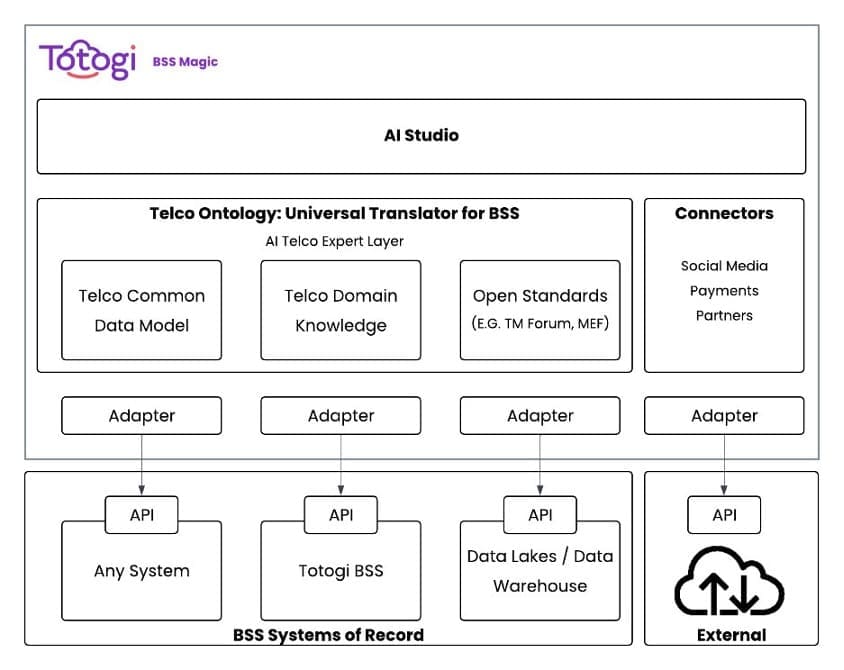
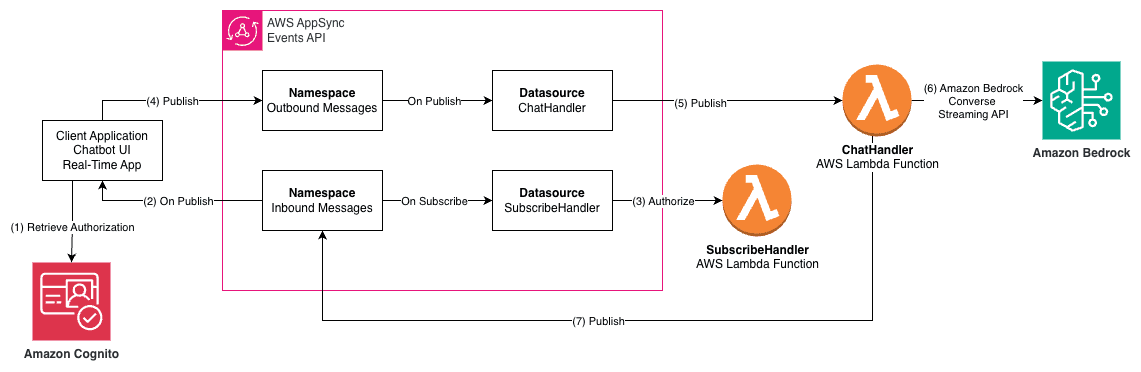
Use Amazon Quick Suite custom action connectors to upload text files to Google Drive using OpenAPI specification
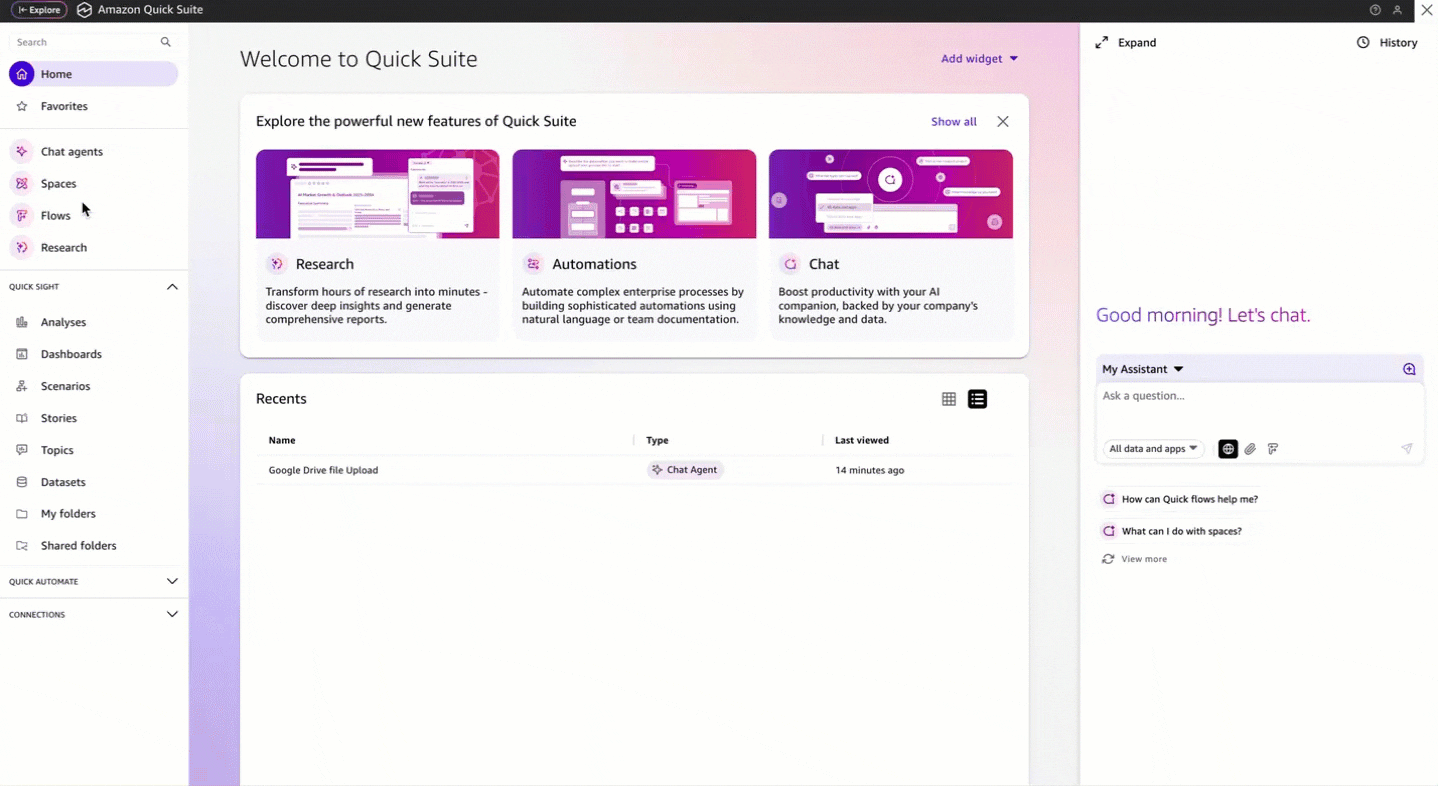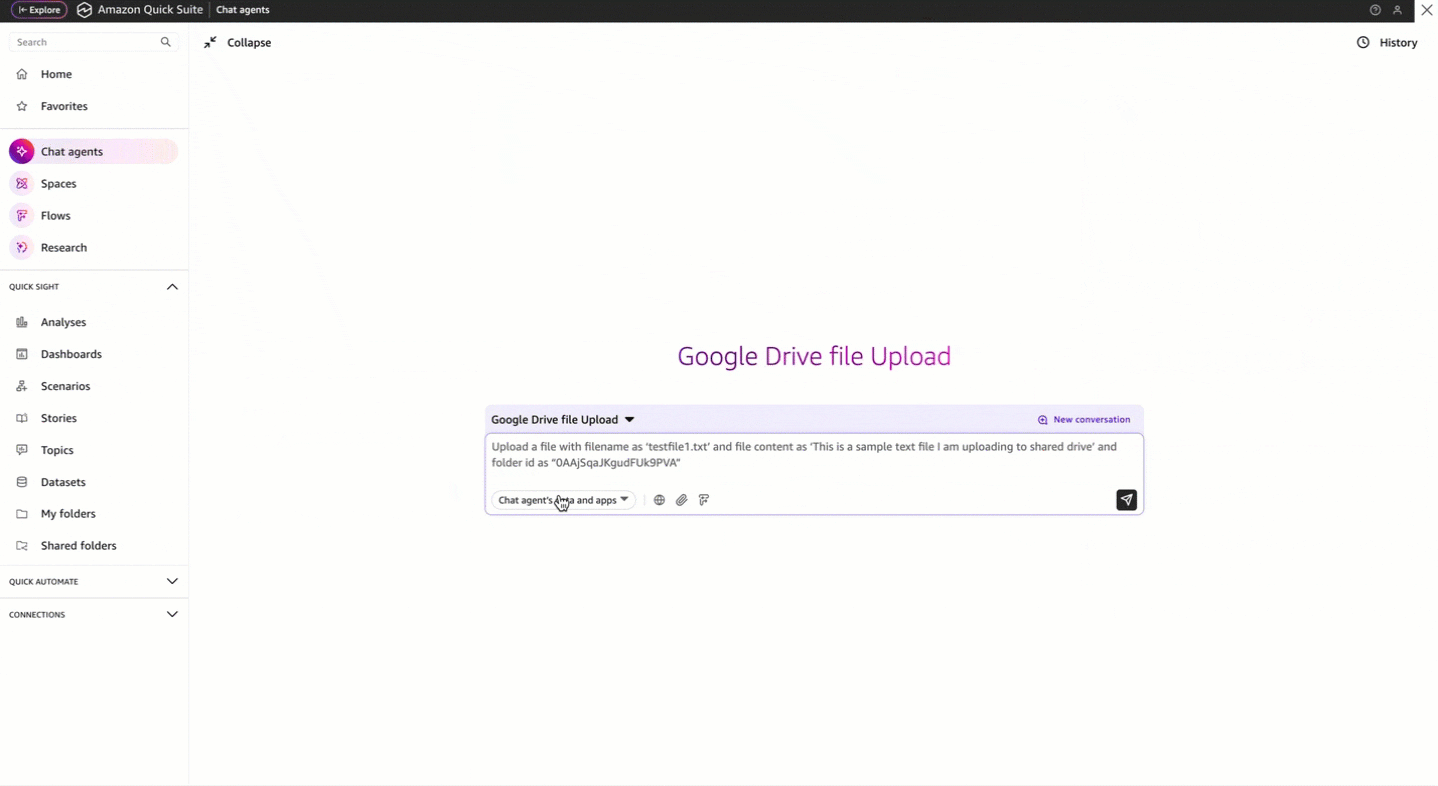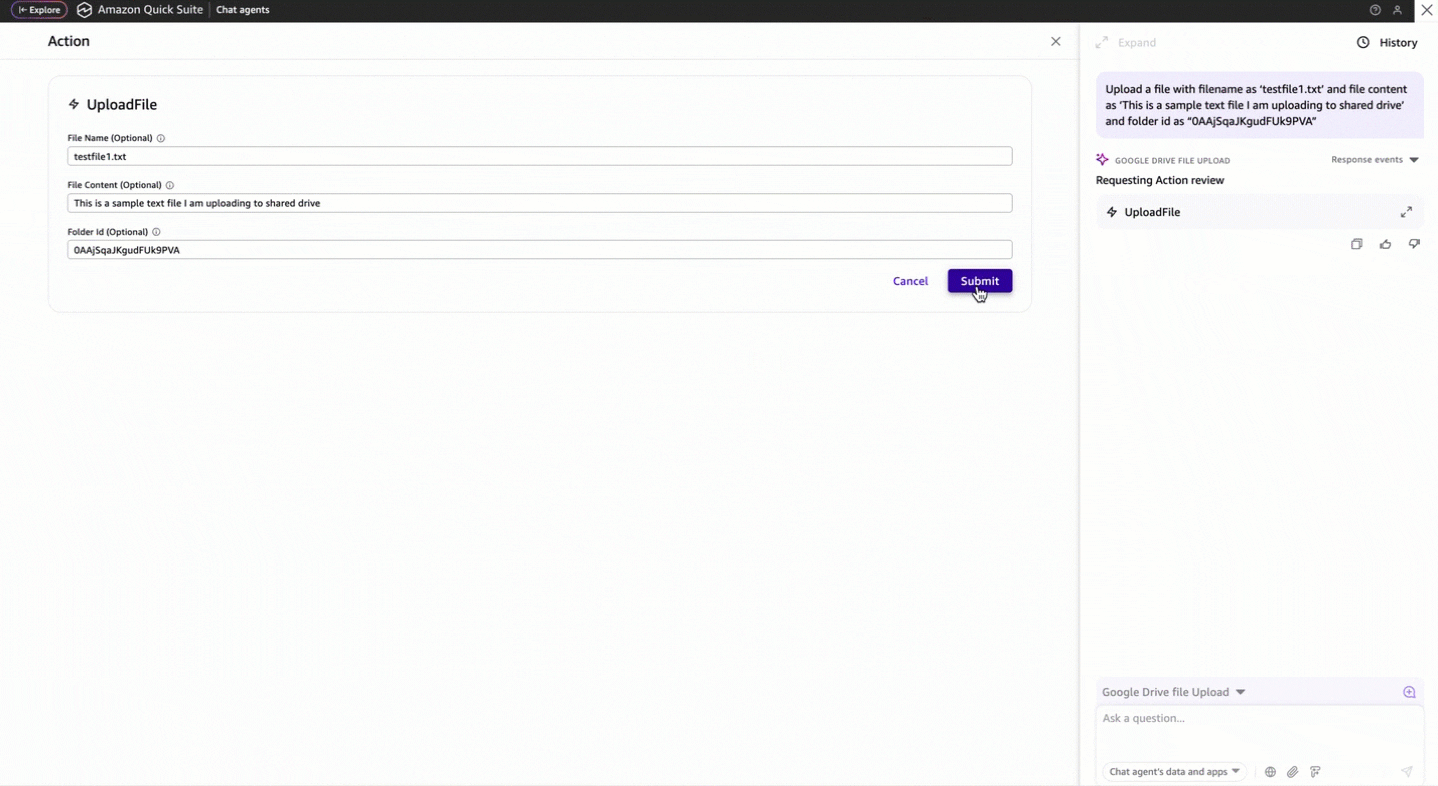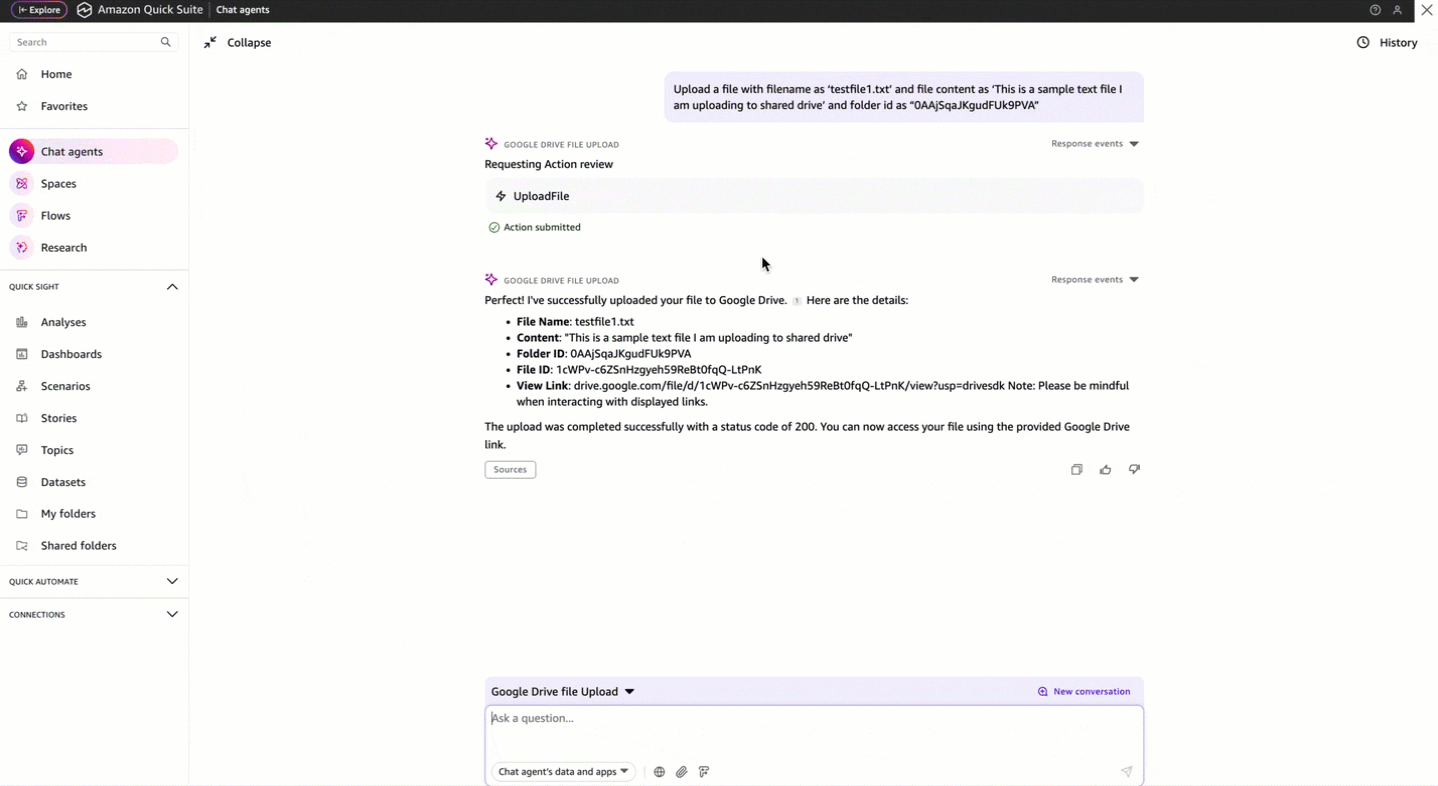
Favorite Many organizations need to manage file uploads across different cloud storage systems while maintaining security and compliance. Although Google Drive provides APIs for integration, organizations often don’t have the technical experts to interact with these APIs directly. Organizations need an intuitive way to handle file uploads using natural language,
Read More![]() Shared by AWS Machine Learning February 4, 2026
Shared by AWS Machine Learning February 4, 2026