Favorite Distributed deep learning model training is becoming increasingly important as data sizes are growing in many industries. Many applications in computer vision and natural language processing now require training of deep learning models, which are growing exponentially in complexity and are often trained with hundreds of terabytes of data.
Favorite This is a guest post by Ramzi Alqrainy, Chief Technology Officer, The Chefz. The Chefz is a Saudi-based online food delivery startup, founded in 2016. At the core of The Chefz’s business model is enabling its customers to order food and sweets from top elite restaurants, bakeries, and chocolate
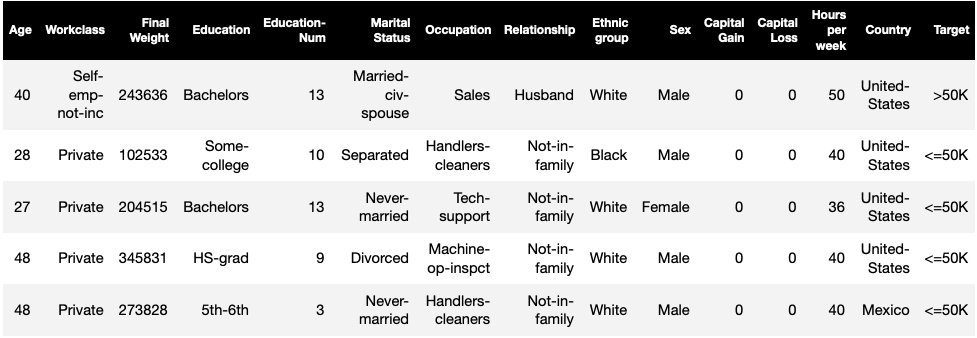
Favorite Bias detection in data and model outcomes is a fundamental requirement for building responsible artificial intelligence (AI) and machine learning (ML) models. Unfortunately, detecting bias isn’t an easy task for the vast majority of practitioners due to the large number of ways in which it can be measured and
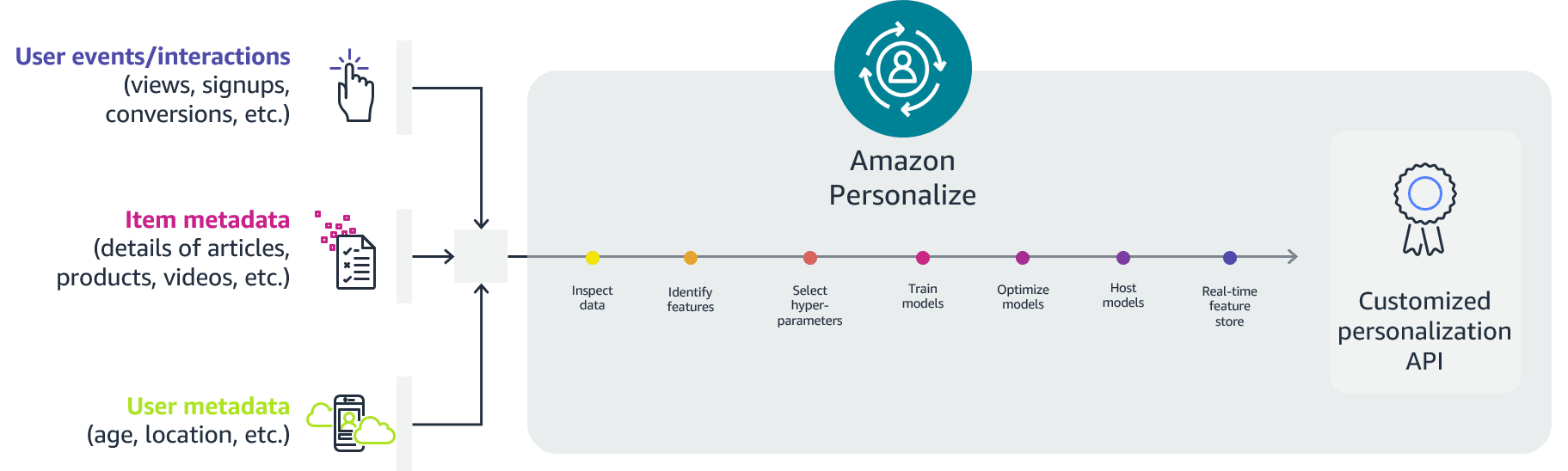
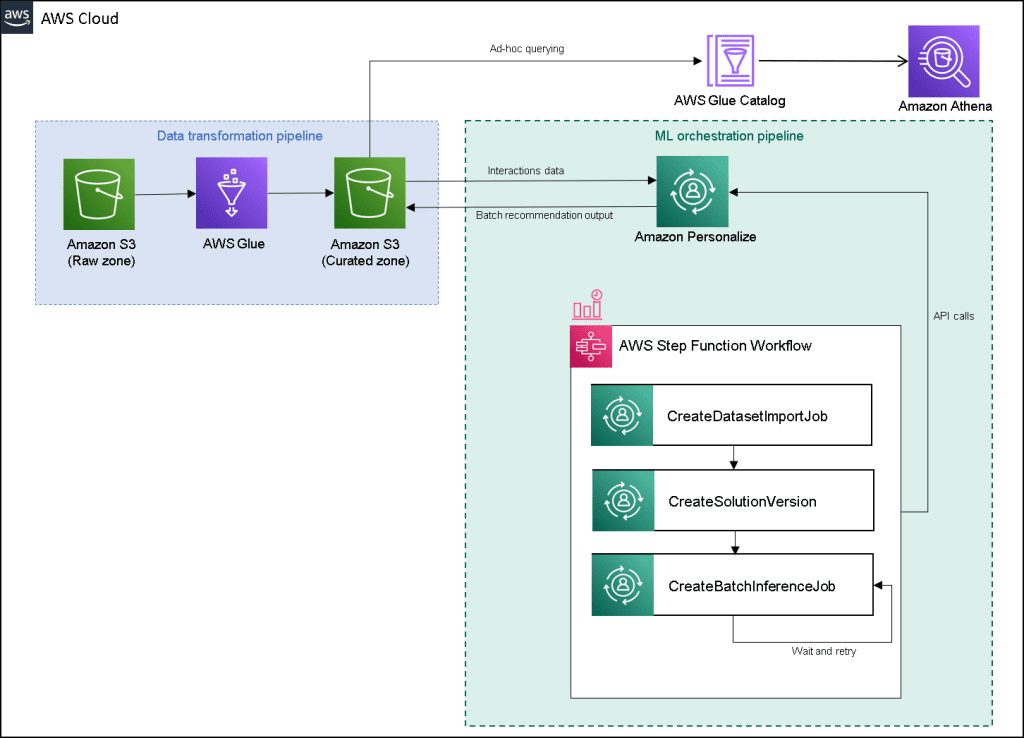
Favorite With personalized content more likely to drive customer engagement, businesses continuously seek to provide tailored content based on their customer’s profile and behavior. Recommendation systems in particular seek to predict the preference an end-user would give to an item. Some common use cases include product recommendations on online retail
Favorite Data preparation is the process of collecting, cleaning, and transforming raw data to make it suitable for insight extraction through machine learning (ML) and analytics. Data preparation is crucial for ML and analytics pipelines. Your model and insights will only be as reliable as the data you use for
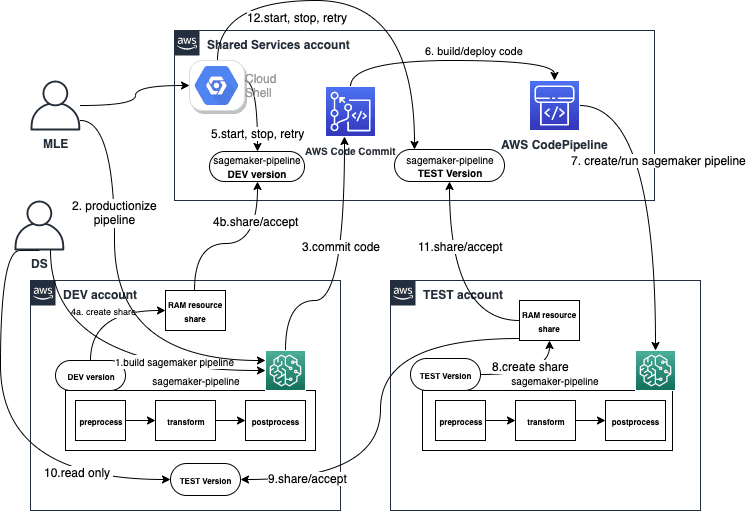
Favorite On August 9, 2022, we announced the general availability of cross-account sharing of Amazon SageMaker Pipelines entities. You can now use cross-account support for Amazon SageMaker Pipelines to share pipeline entities across AWS accounts and access shared pipelines directly through Amazon SageMaker API calls. Customers are increasingly adopting multi-account
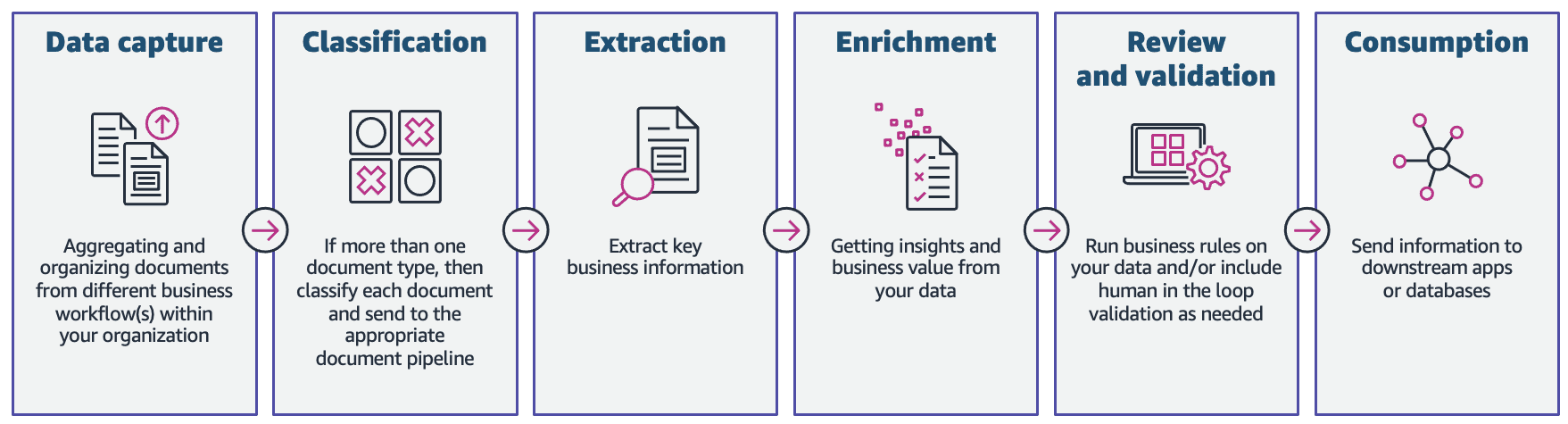
Favorite Organizations in the lending and mortgage industry process thousands of documents on a daily basis. From a new mortgage application to mortgage refinance, these business processes involve hundreds of documents per application. There is limited automation available today to process and extract information from all the documents, especially due
Favorite In December 2020, AWS announced the general availability of Amazon SageMaker JumpStart, a capability of Amazon SageMaker that helps you quickly and easily get started with machine learning (ML). JumpStart provides one-click fine-tuning and deployment of a wide variety of pre-trained models across popular ML tasks, as well as
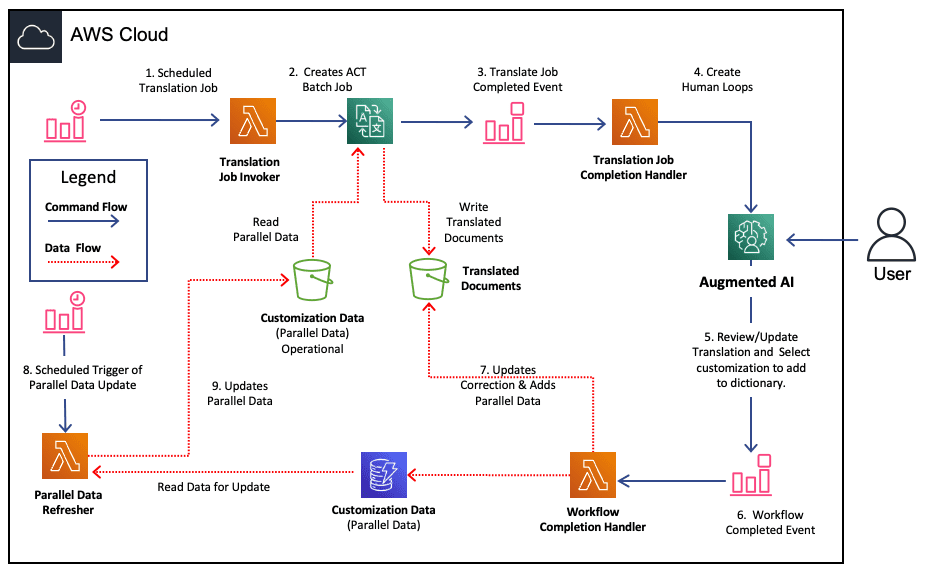
Favorite In the digital world, providing information in a local language isn’t novel, but it can be a tedious and expensive task. Advancements in machine learning (ML) and natural language processing (NLP) have made this task much easier and less expensive. We have seen increased adoption of ML for multi-lingual
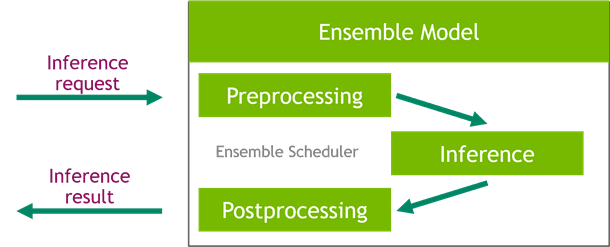
Favorite Machine learning (ML) model deployments can have very demanding performance and latency requirements for businesses today. Use cases such as fraud detection and ad placement are examples where milliseconds matter and are critical to business success. Strict service level agreements (SLAs) need to be met, and a typical request